
















2022年8月に一般公開された画像生成AI「Stable Diffusion」を簡単にWindowsローカル環境に導入でき、コマンドラインではなくブラウザ上に表示されるユーザーインターフェース(UI)から操作可能にするツールがAUTOMATIC1111版Stable Diffusion web UIです。AUTOMATIC1111版Stable Diffusion web UIはただ画像を生成するだけではなく、画像生成時に入力する文字列(プロンプト)について複数の組み合わせを一気にチェックしたり、画像生成の条件を複数設定して一度に画像を生成したりするなど、Stable DiffusionのUIとしては決定版といってもいいほど機能が充実しています。そんなAUTOMATIC1111版Stable Diffusion web UIでは、AIで生成した画像を解析してプロンプトを表示する「CLIP interrogator」が搭載されています。インターネットの掲示板やSNSで誰かがAIで生成した画像を見かけても、どういったプロンプトで作られたのかが一切公開されていないという時にめちゃくちゃ役立ちそうだったので、実際に使ってみました。
GitHub – AUTOMATIC1111/stable-diffusion-webui-feature-showcase: Feature showcase for stable-diffusion-webui
https://github.com/AUTOMATIC1111/stable-diffusion-webui-feature-showcase#clip-interrogator
AUTOMATIC1111版Stable Diffusion web UIをローカル環境やGoogle Colaboratory(Google Colab)で動かすためのインストール方法やアップデート方法は以下の記事を読むとよくわかります。

AUTOMATIC1111版Stable Diffusion web UIの基本的な使い方は、以下の記事にまとめられています。

AUTOMATIC1111版Stable Diffusion web UIは、Stable Diffusionで画像を生成できるだけでなく、画像を生成するために便利な機能が多く搭載されています。例えば、AUTOMATIC1111版Stable Diffusion web UIのScript機能で使えるPrompt matrixやX/Y protを使うと、プロンプトやパラメーターを変えたことによる差が一目でわかるように画像を生成可能。具体的な使い方は以下の記事を読むとよくわかります。

AUTOMATIC1111版Stable Diffusion web UIを起動してみました。

CLIP interrogatorで画像のプロンプトを調べるには、読み込ませた画像から新たな画像を生成する「img2img(image to image)」を使います。「img2img」タブをクリック。
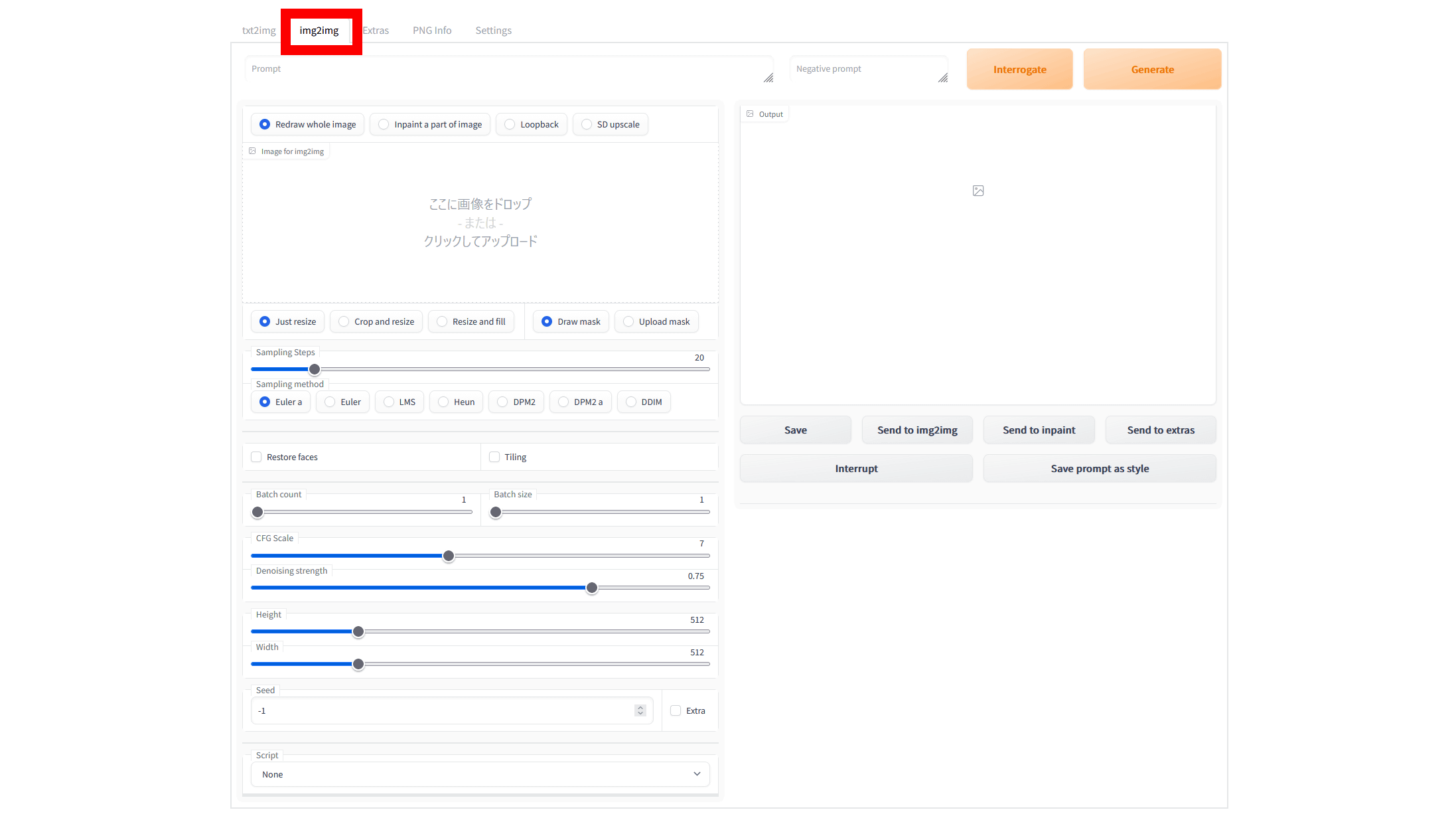
左カラムの「Image for img2img」の欄をクリックしてプロンプトを調べたい画像を選択、あるいは画像を直接「Image for img2img」の欄にドラッグ&ドロップします。
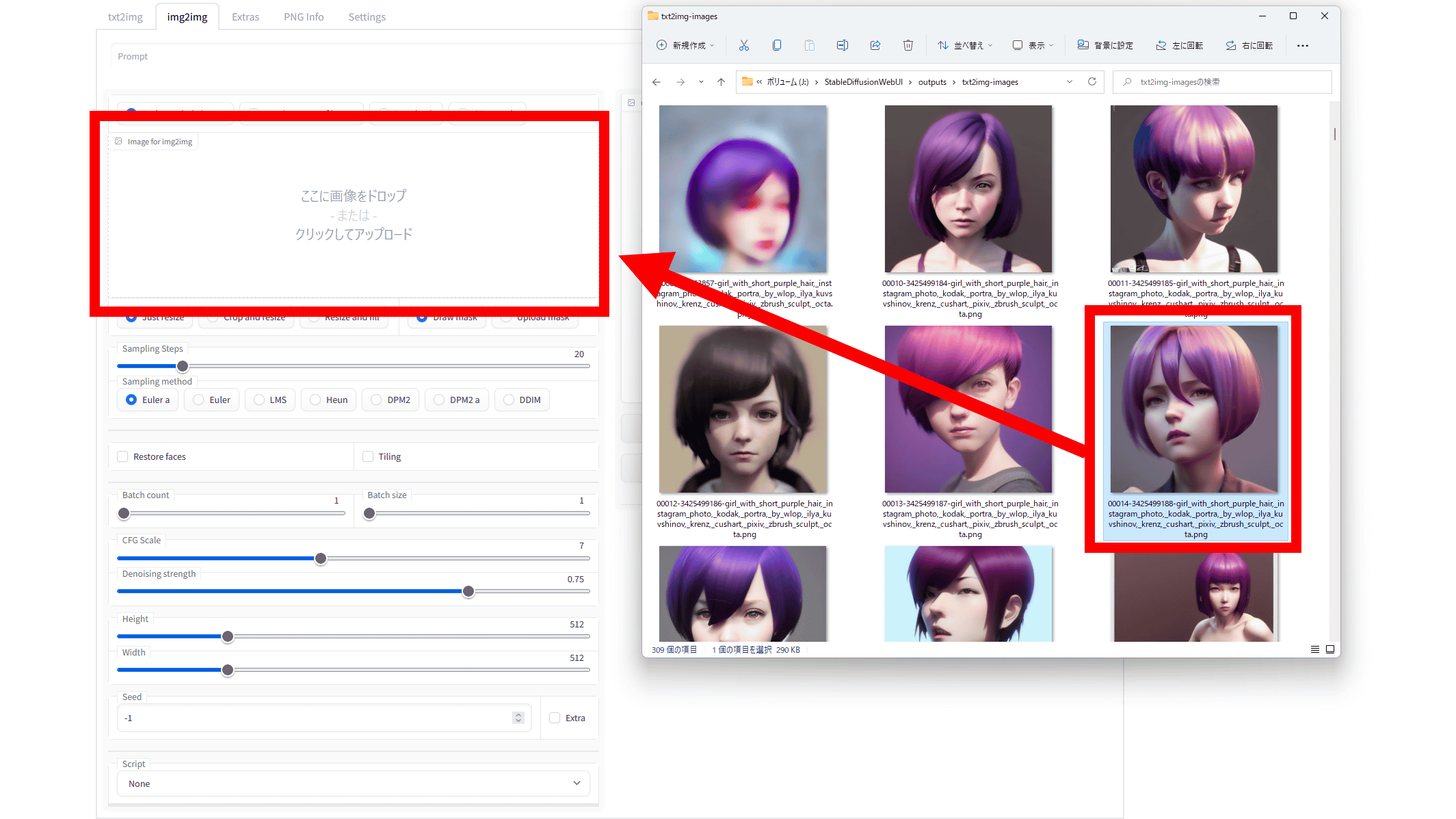
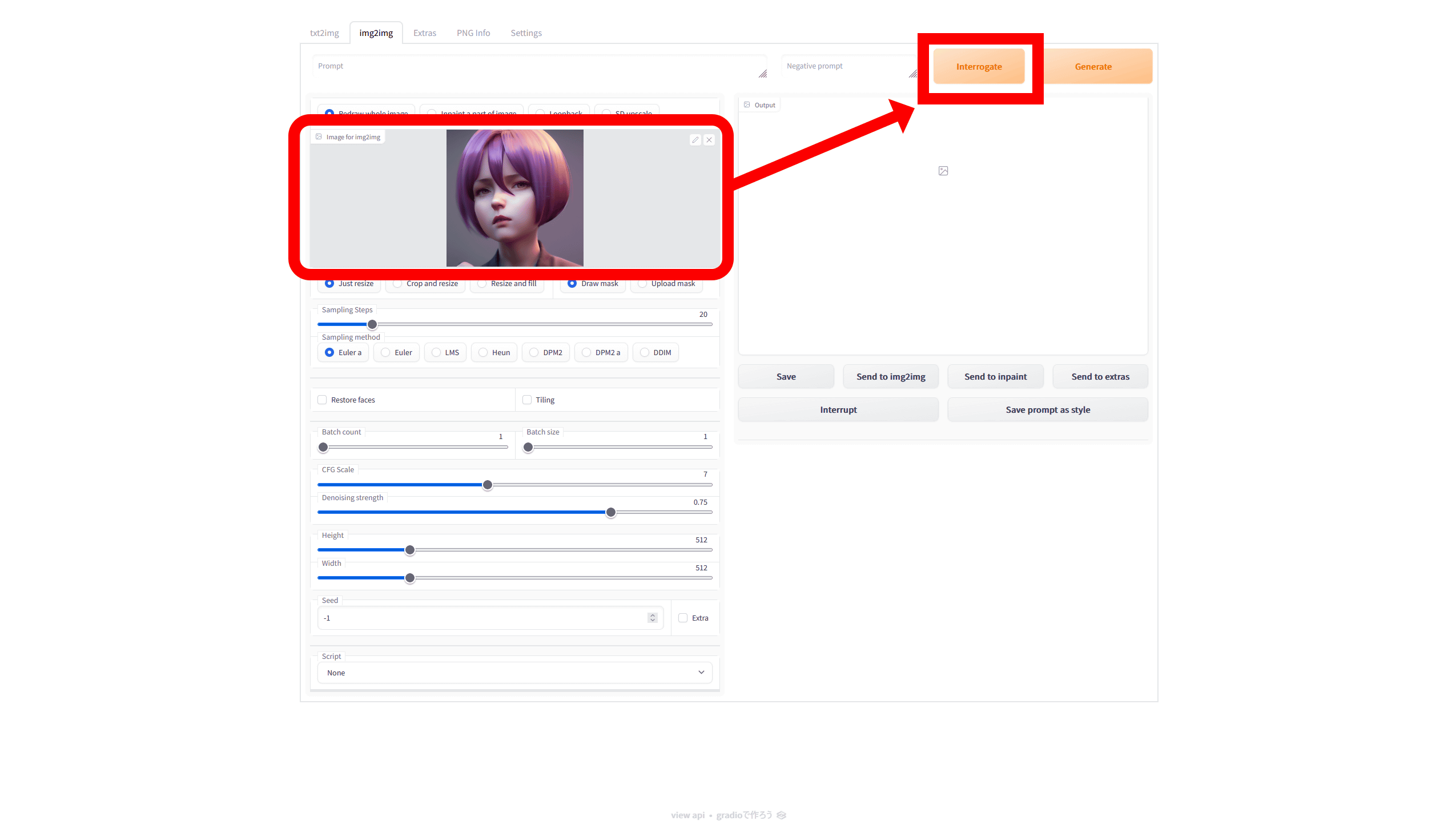
画像が読み込まれると、「Image for img2img」の欄に画像が表示されるので、「Interrogate」ボタンをクリック。
初回は必要なモデルのダウンロードが行われるので数分待ちます。
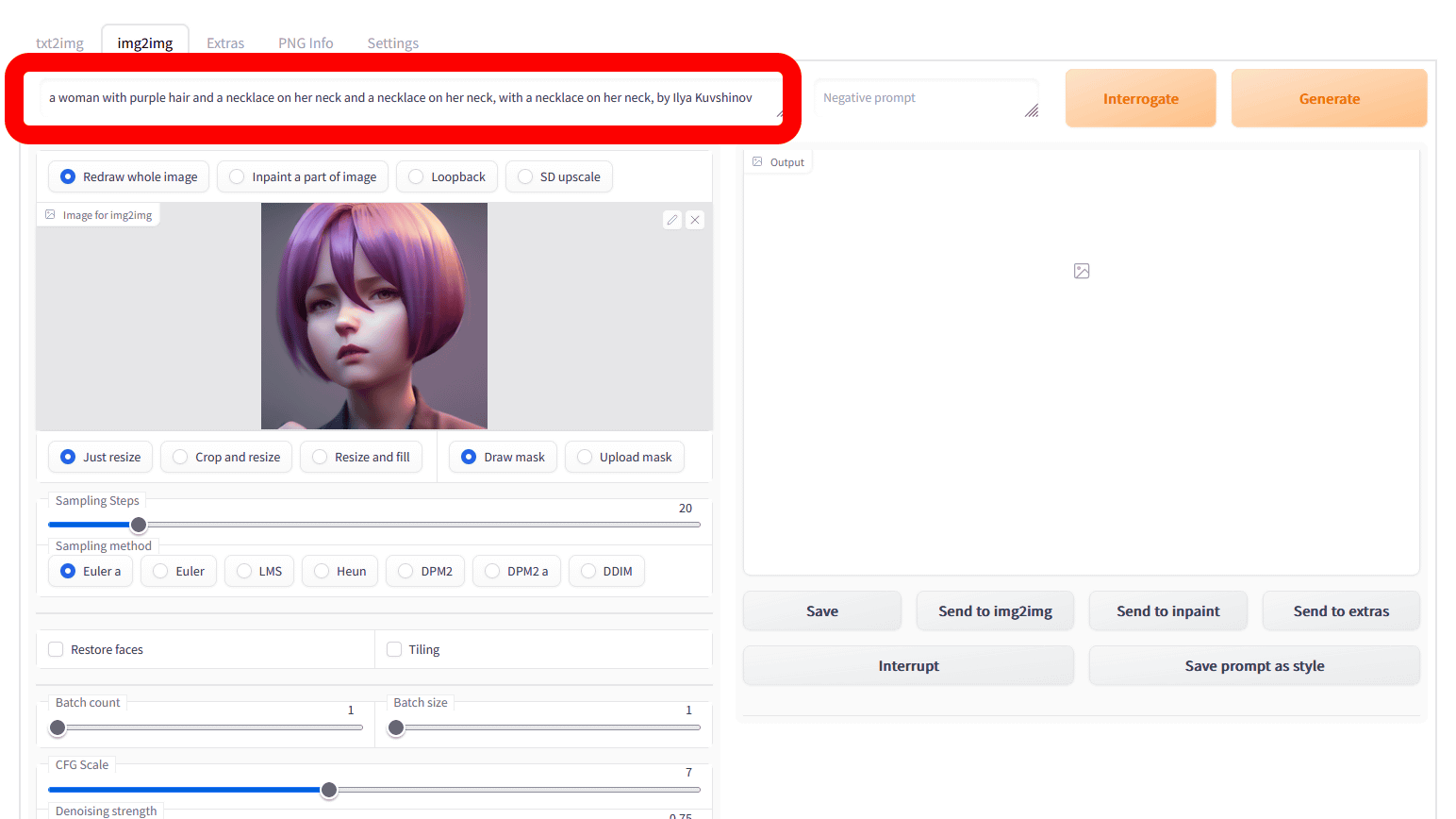
すると、AUTOMATIC1111版Stable Diffusion web UI上部にある入力欄に「a woman with purple hair and a necklace on her neck and a necklace on her neck, with a necklace on her neck, by Ilya Kuvshinov(紫髪の女性で首にネックレスを付けていて首にネックレスを付けている、首にネックレスをつけている、 Ilya Kuvshinov風)」というプロンプトが表示されました。なぜかやたらネックレスを首につけていることがアピールされましたが、元の生成プロンプトは「girl with short purple hair, instagram photo, kodak portra, by wlop, ilya kuvshinov, Krenz Cushart, pixiv, zblush sculpt(紫色のショートヘアの女の子、インスタグラムの写真、コダック PORTRA, WLOP風、Ilya Kuvshinov風、Krenz Cushart風、Pixiv、Zblushの作品)」で、紫髪であることはもちろん、Ilya Kuvshinov風という画風についても指摘できていました。なお、CLIP interrogatorは画像からプロンプトを生成する「BLIPモデル」と、あらかじめ用意されたリストから言葉を選択する「CLIPモデル」の2つで構成されているとのこと。
ただしCLIP interrogatorは必要なVRAMが「12GB以上」となっているので、VRAM搭載量が足りない低スペックのGPUだと使うことができません。Google Colabは無料版でもVRAMが最低12GBのGPUを使えるとのことなので、Google ColabでCLIP interrogatorを使えるかどうかを試してみました。
Google ColabでAUTOMATIC1111版Stable Diffusion web UIをインストール。割り当てられたGPUはTesla T4で、VRAMは16GB GDDR6です。

インストールが終わったら、生成されたURLにアクセスしてAUTOMATIC1111版Stable Diffusion web UIを開きます。
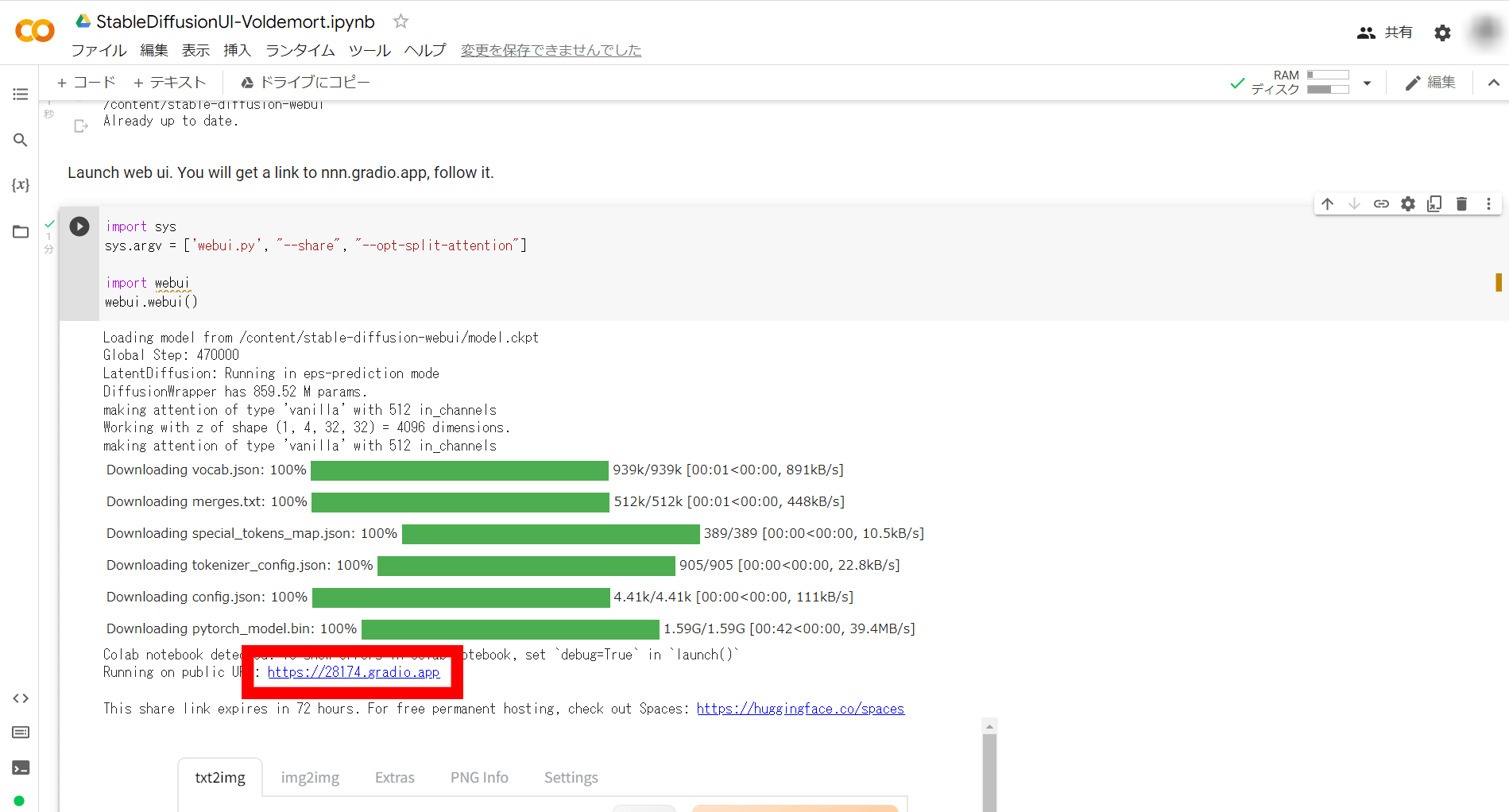
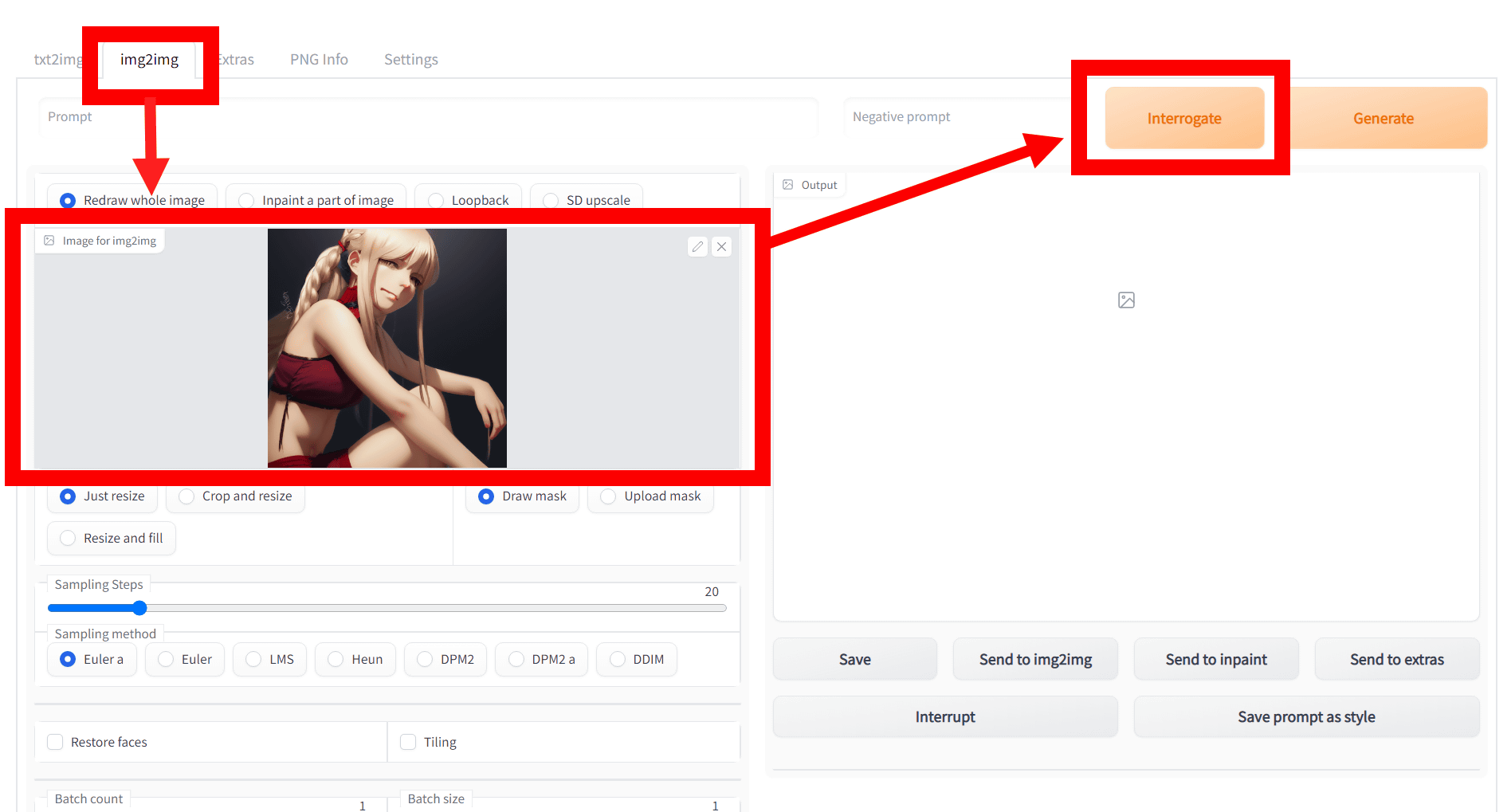
操作はローカル版と同じ。「img2img」のタブをクリックし、「Image to img2img」の欄に解析したい画像を読み込ませて、「Interrogate」をクリック。
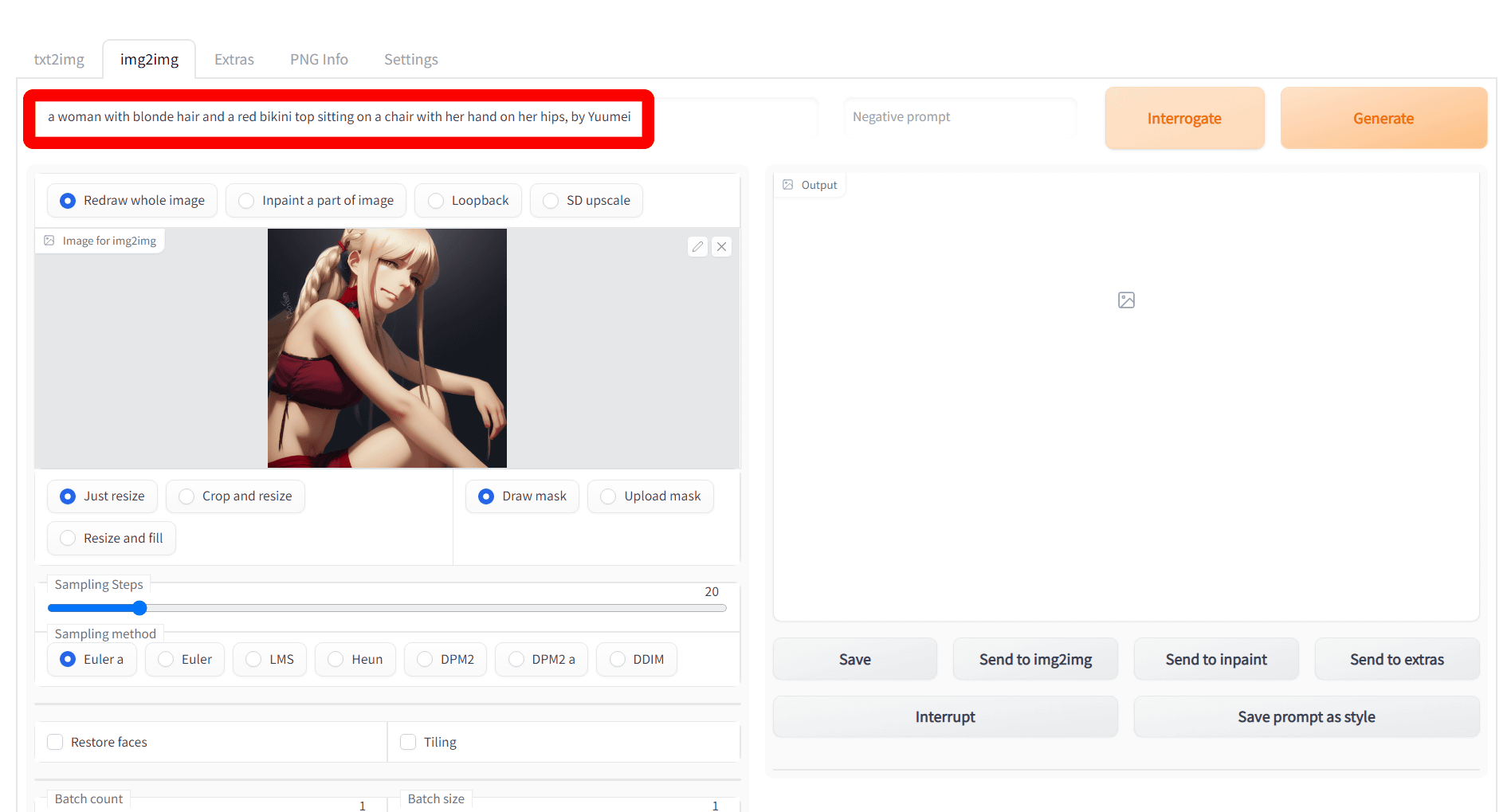
すると、画像からプロンプトが生成され、Google Colabで動作するAUTOMATIC1111版Stable Diffusion web UIでもCLIP interrogatorを利用可能であることが確認できました。
CLIP interrogatorに関する設定は「Settings」タブから変更可能。以下の赤枠で囲った部分がCLIP interrogatorに関する部分です。
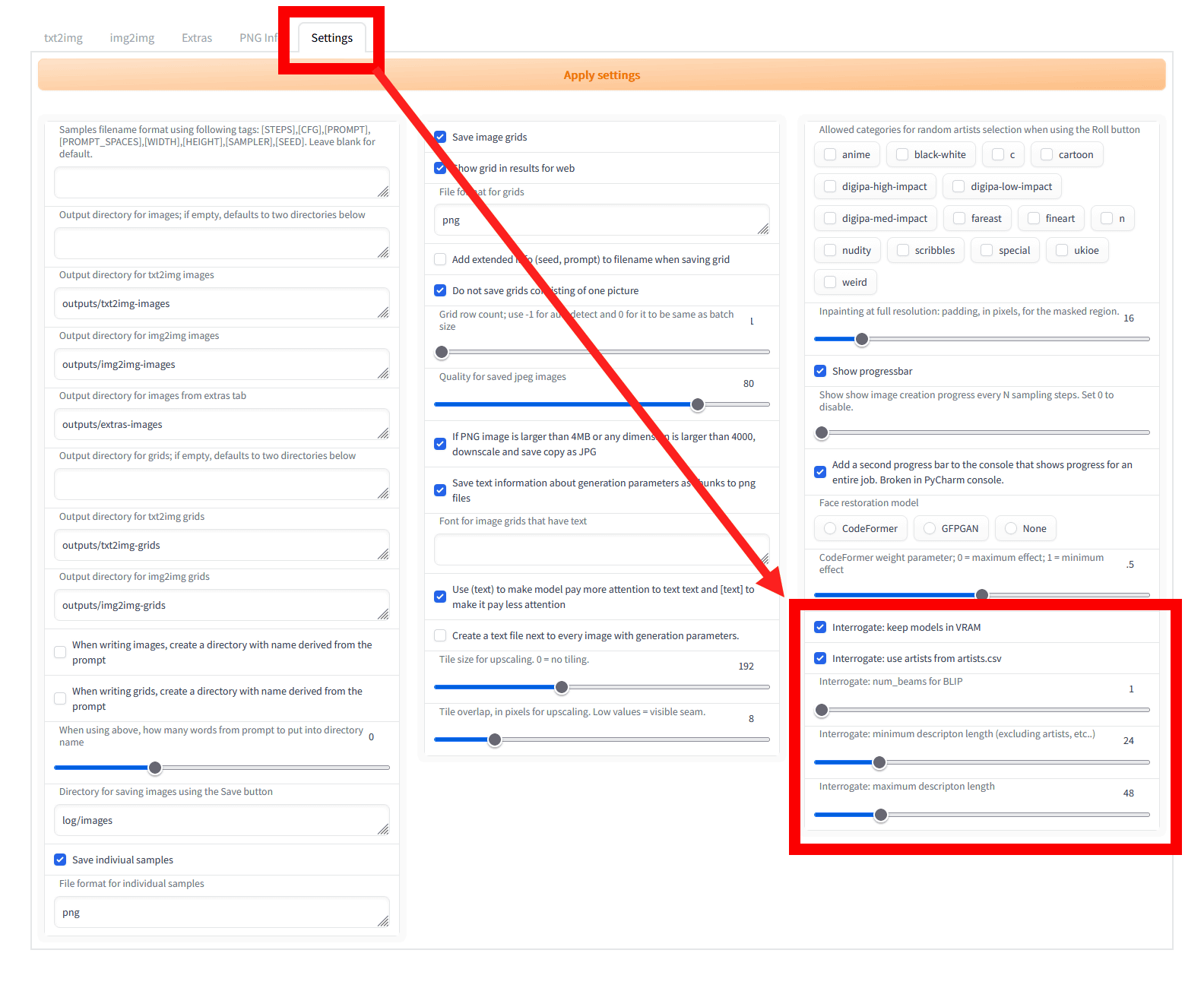
各項目については以下の通り。
・Interrogate: keep models in VRAM:チェックが入っていると、プロンプトの解析後もVRAMにCLIP Interrogatorのモデルデータを解放せず維持します。毎回読み込む必要がなくなるのでその分だけ高速化が期待できます。VRAMが多いユーザー向け。
・Interrogate: use artists from artists.csv:チェックが入っていると、CLIPモデル用のデフォルトリストである「artists.csv」を使う。なお、AUTOMATIC1111版Stable Diffusion web UI本体と同じディレクトリに「interrogate」フォルダを作成し、プロンプトと説明をまとめた独自のテキストファイルを入れることも可能。テキストファイルの例はここで公開されています。
・Interrogate: num_beams for BLIP:BLIPモデルによって生成されるプロンプトの最初の部分でどこまで詳細に描写するかのレベル。数値が高いほど、最初の部分で細かく描写されます。
・Interrogate: minimum descripton length:BLIPモデルによって生成されるプロンプトの最小長
・Interrogate: maximum descripton length:BLIPモデルによって生成されるプロンプトの最大長
この記事のタイトルとURLをコピーする

