














お気に入りのYouTubeチャンネルを登録して動画をダウンロードし、構築したメディアサーバーでインデックスして検索可能にするオープンソースのツール「Tube Archivist」は、ブラウザの拡張機能を連携させることで簡単に使えるとのことで、実際に試してみました。
Tube Archivist
https://www.tubearchivist.com/
GitHub – tubearchivist/tubearchivist: Your self hosted YouTube media server
https://github.com/tubearchivist/tubearchivist
Tube Archivist Companion – Firefox (ja) 向け拡張機能を入手
https://addons.mozilla.org/ja/firefox/addon/tubearchivist-companion/
TubeArchivist Companion – Chrome ウェブストア
https://chrome.google.com/webstore/detail/tubearchivist-companion/jjnkmicfnfojkkgobdfeieblocadmcie
まず、GitHubのぺージにある通り、Docker ComposeでTube Archivistのメディアサーバーを構築し、ブラウザの拡張機能をインストールします。Tube Archivist用のブラウザ拡張はChrome版とFirefox版がありますが、今回はChrome版をインストールするため、Chromeウェブストアの配布ページで「Chromeに追加」をクリック。

「拡張機能を追加」をクリック。

次にTube Archivistのメディアサーバーと拡張機能を連携します。連携にはTube ArchivistのメディアサーバーのURLとAPIトークンが必要になります。APIトークンを取得するには、メディアサーバーのページから設定アイコンをクリック。

「Integrations」にある「API token」の「Show」ボタンをクリックします。

すると、APIトークンの文字列が表示されるので、これをコピーします。
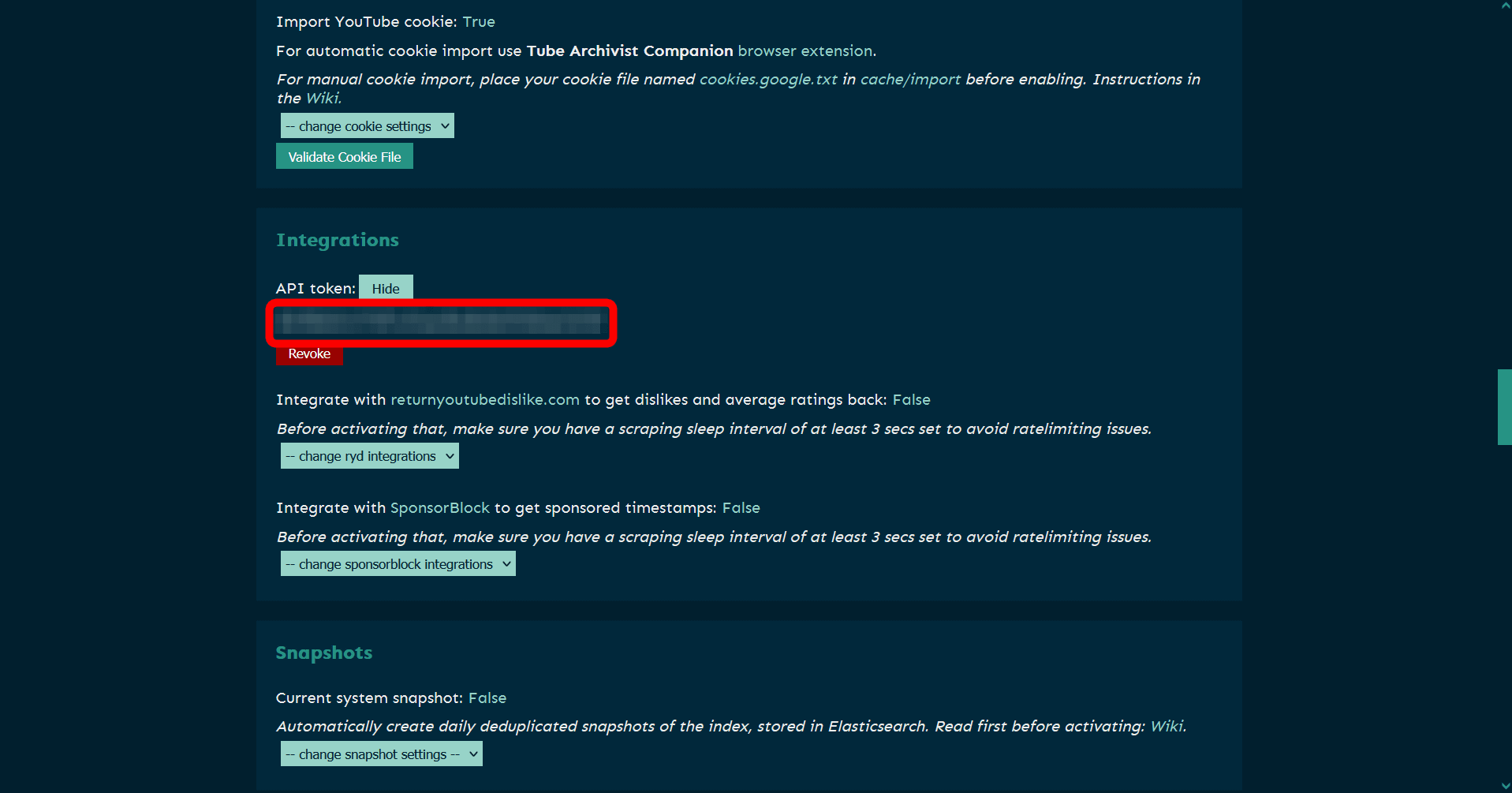
次にブラウザ右上の拡張機能アイコンをクリックし、「Tube Archivisit URL」にメディアサーバーのURLを、「Tube Archivisit API Key」にコピーしたAPIトークンをペーストし、「Save」をクリックします。これでメディアサーバーと拡張機能の連携は完了。
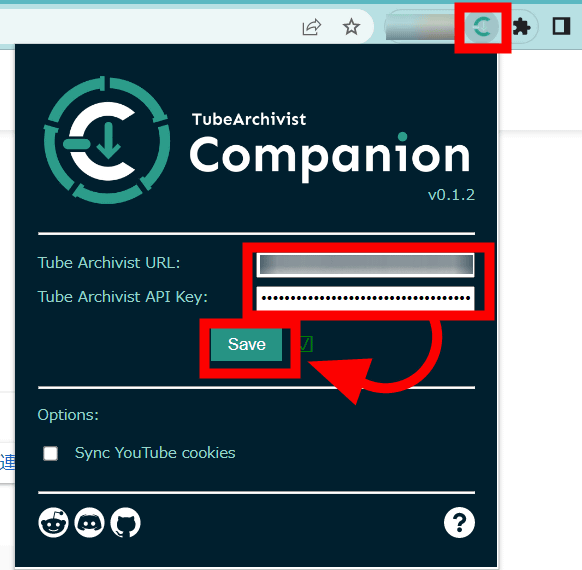
試しにGIGAZINEのYouTubeチャンネルをChromeで開いてみると、チャンネル登録ボタンのところに「Subscribe」という黒いボタンが追加されているので、これをクリック。

すると、メディアサーバーのページの「Channels」にGIGAZINEのYouTubeチャンネルが表示されました。

さらに「downloads」のタブをクリックし、「Rescan subscription」をクリックすると、GIGAZINEのYouTubeチャンネルで公開されている動画が99本分スキャンされ、ダウンロードキューに追加されます。この段階ではダウンロードは完了していません。

「Start download」をクリックすると、ダウンロードキューに追加された動画がすべてメディアサーバーにダウンロードされます。

ダウンロード中の画面がこんな感じ。

「home」タブをクリックすると、ダウンロードされた動画が「Recent Videos」に並んでいます。
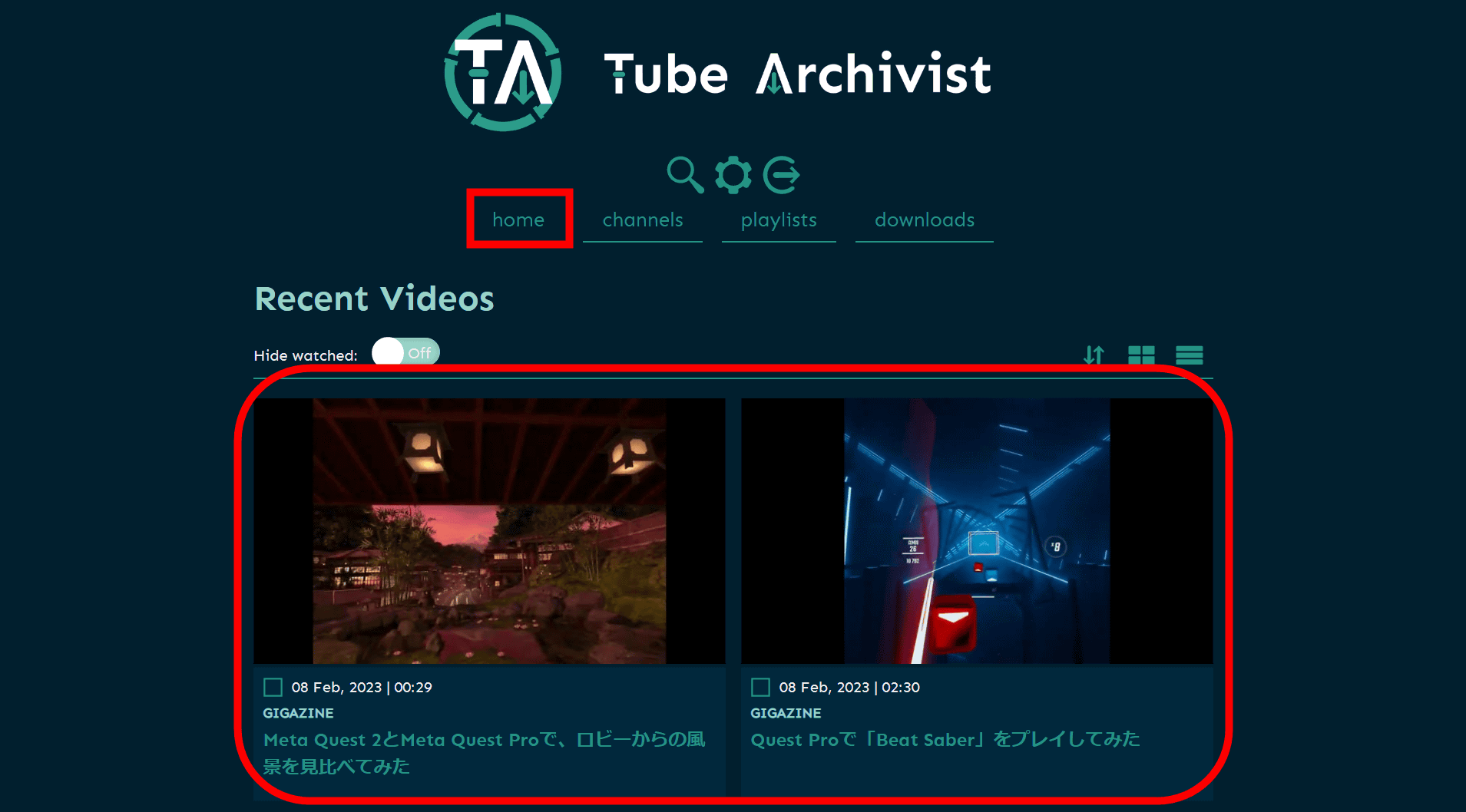
サムネイルをクリックすると、そのままブラウザ上で再生されます。
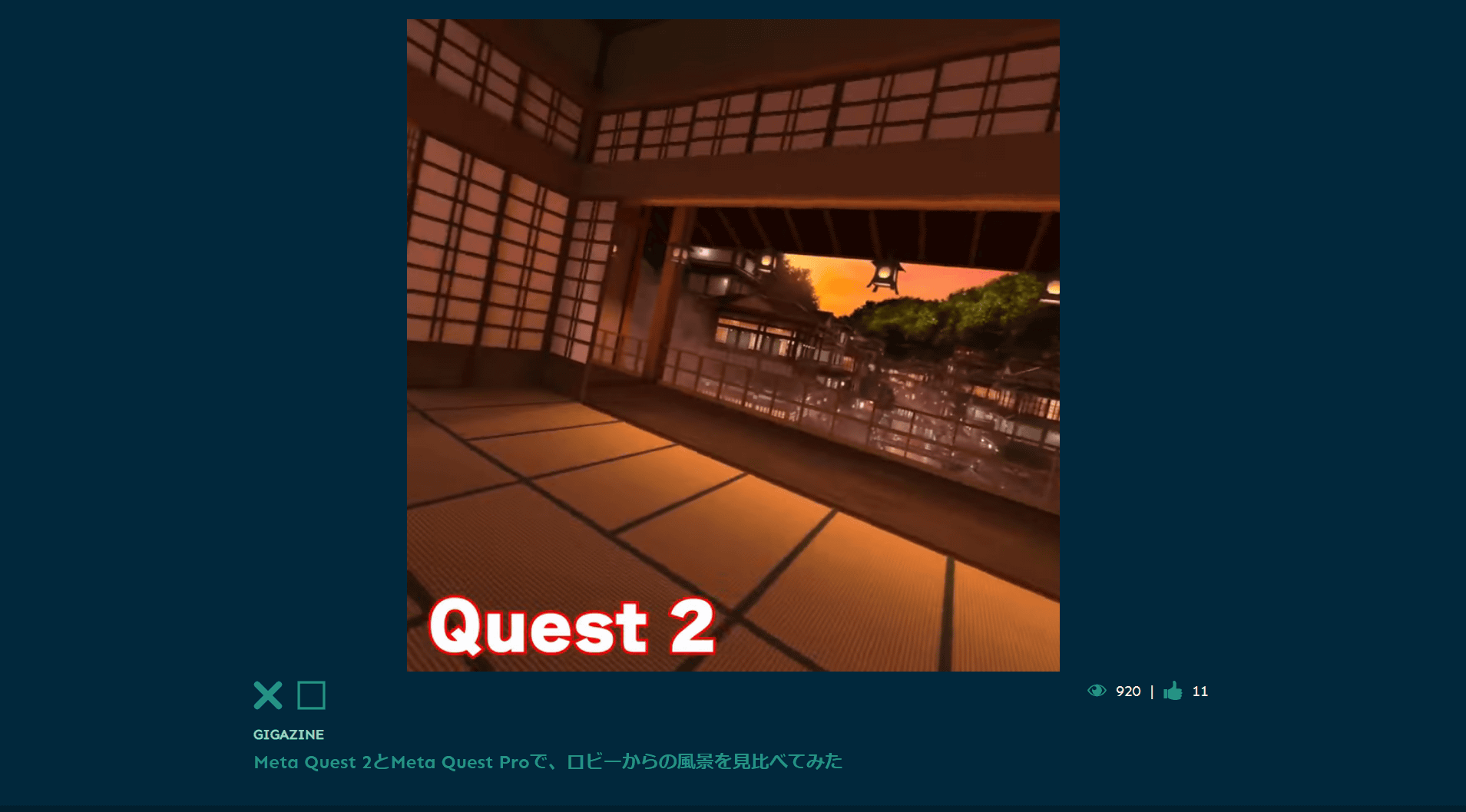
なお、今回はSynologyのNAS上でメディアサーバーを構築したのですが、参考程度にアイドル状態のCPU使用率とメモリ使用量はこんな感じ。
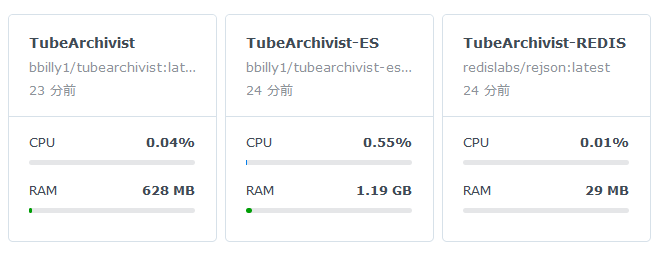
そして、ダウンロード中のCPU使用率とメモリ使用量が以下。特に3つあるDockerイメージのうち、「TubeArchivist」の使用メモリが約630MBから約5.9GBに大きく増加しています。
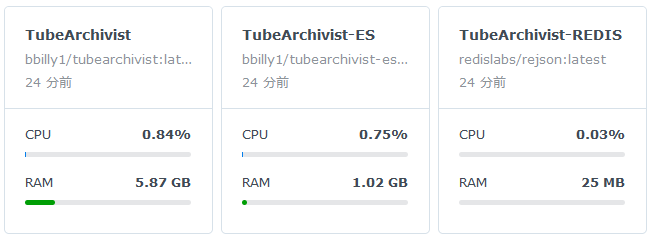
リソースモニタでCPUとメモリの使用率の推移を見るとこんな感じで、ダウンロードが始まるとドカンと上がっています。Tube Archivistの開発者はGitHubで「必要なRAM容量は、小規模なテストセットアップの場合だと約2GB、中規模から大規模なインストールの場合は約4GB必要」とコメントしていますが、実際は4GBでもギリギリかもしれません。
この記事のタイトルとURLをコピーする

