画像生成AI「DALL・E2」や文章生成AI「GPT-3」「InstructGPT」などを開発するAI研究団体のOpenAIが、2022年9月に高性能な文字起こしAI「Whisper」を発表しました。オープンソースのWhisperはリポジトリが一般公開されており、日本語にも対応しているとのことで、オンライン実行環境のGoogle Colaboratory(Google Colab)やローカルのWindows環境に導入して使ってみました。
Introducing Whisper
https://openai.com/blog/whisper/
GitHub – openai/whisper
https://github.com/openai/whisper
◆Hugging Faceの体験版を使ってみる
◆Google Colabに導入して使ってみる
◆Windows環境に導入してみる
・Pythonのインストール
・CUDAのインストール
・PyTorchのインストール
・ffmpegのインストール
・Whisperのインストール
◆Windowsに導入したWhisperで文字起こしをしてみる
◆Hugging Faceの体験版を使ってみる
Whisperを使った録音音声からの文字起こしを、オンラインAIフレームワークのHugging Faceで手っ取り早く試すことができます。ただし、モデルは一番小さいので精度も最も低くなっています。
Whisper – a Hugging Face Space by openai
https://huggingface.co/spaces/openai/whisper
上記サイトにアクセスします。左側にある「Record from microphone」をクリックします。

ブラウザからマイクの使用許可を求められるので、「許可する」をクリック。

今回は夏目漱石の「我輩は猫である」の冒頭部分を読み上げてみました。録音は最大30秒までで、完了するとプレイヤーが表示されます。右側にある「Transcribe」をクリック。

すると、プレイヤーの下に書き起こした文章が表示されました。「我輩」が「我が灰」、「検討がつかぬ」が「検討がつかね」、「薄暗い」が「すぐらい」となっていますが、漢字変換やオノマトペのカタカナ表記も含めて、日本語としておおむね正確に書き起こせていることがわかります。

なお、Whisperのモデルにはパラメーターサイズが3900万の「tiny」、7400万の「base」、2億4400万の「small」、7億6900万の「medium」、15億5000万の「large」の5種類があります。要求VRAMはtinyとbaseが最大1GB、smallが最大2GB、mediumが最大5GB、largeが最大10GBとなっています。英語に特化したenモデルもありますが、基本は他言語対応。
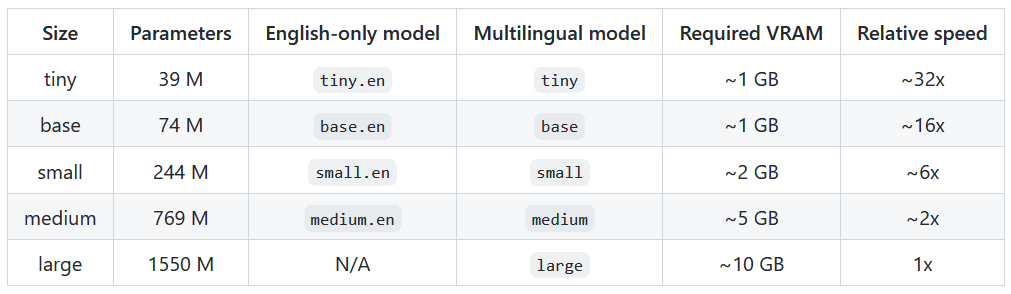
以下は各言語のエラー報告率(WER)を示したもので、WERが低いほど高い精度で文字起こしできることを意味します。これによると、Japanese(日本語)は上位6番目となっています。
◆Google Colabに導入して使ってみる
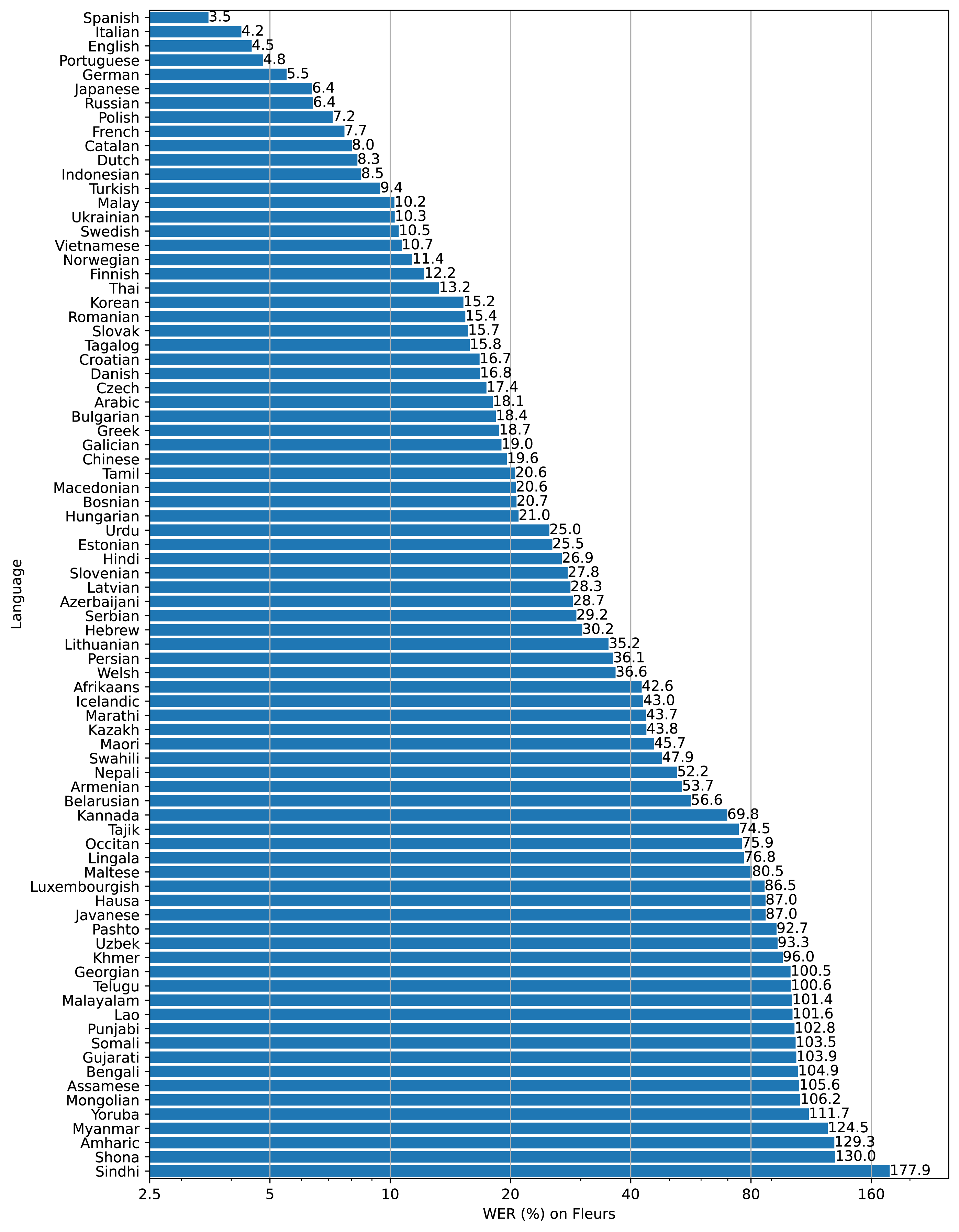
Whisperはオンライン実行環境であるGoogle Colabに導入することが可能です。まず、Googleアカウントにログインした状態でGoogle Colabにアクセスし、「ノートブックを新規作成」をクリック。
右上にある「接続」をクリックして、ランタイムに接続します。
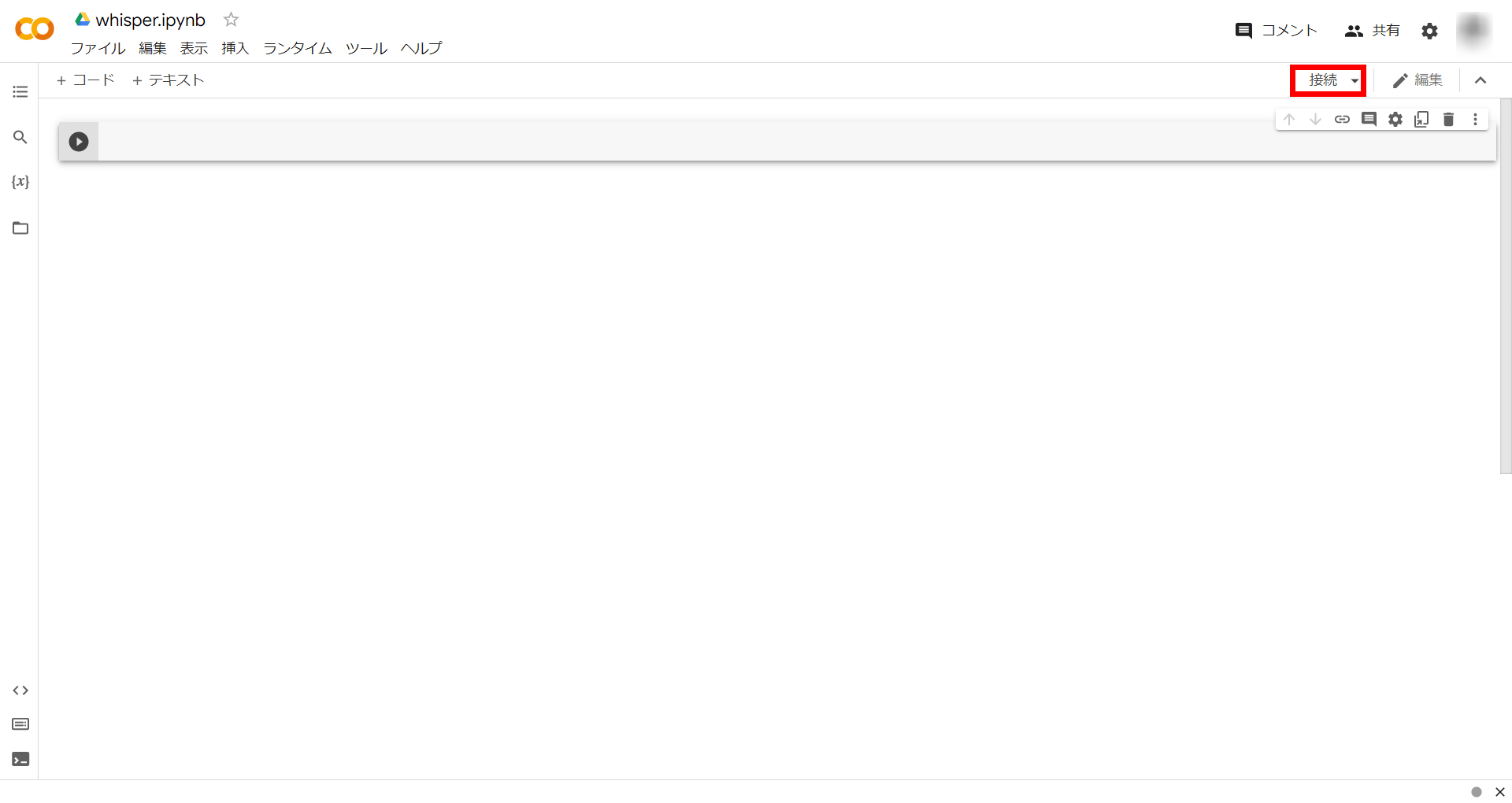
接続が完了したら、「RAM」「ディスク」の部分をクリックし、一番下の「ランタイムのタイプを変更」をクリック。
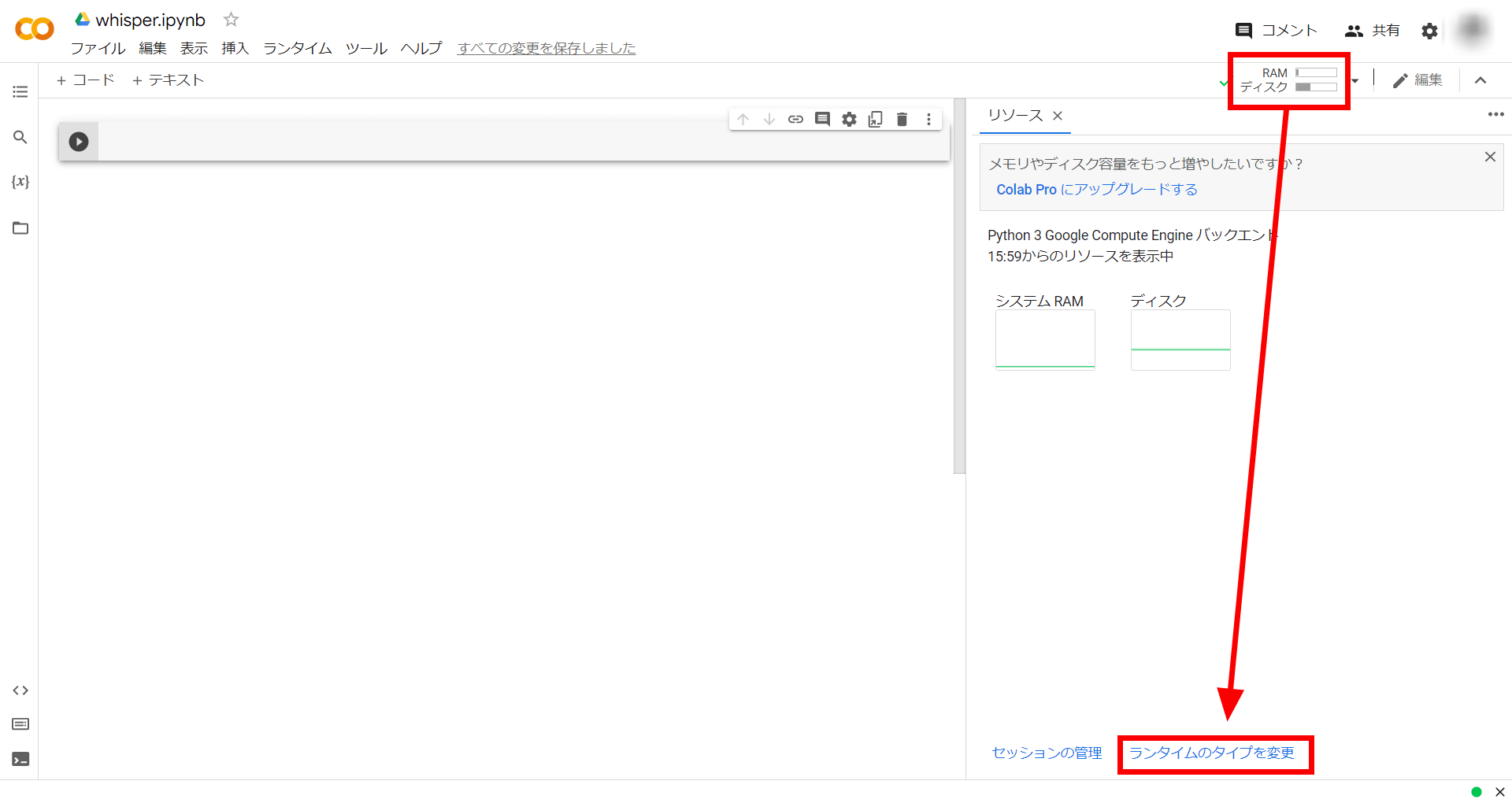
ハードウェアアクセラレータを「GPU」に変更し、「保存」をクリックします。
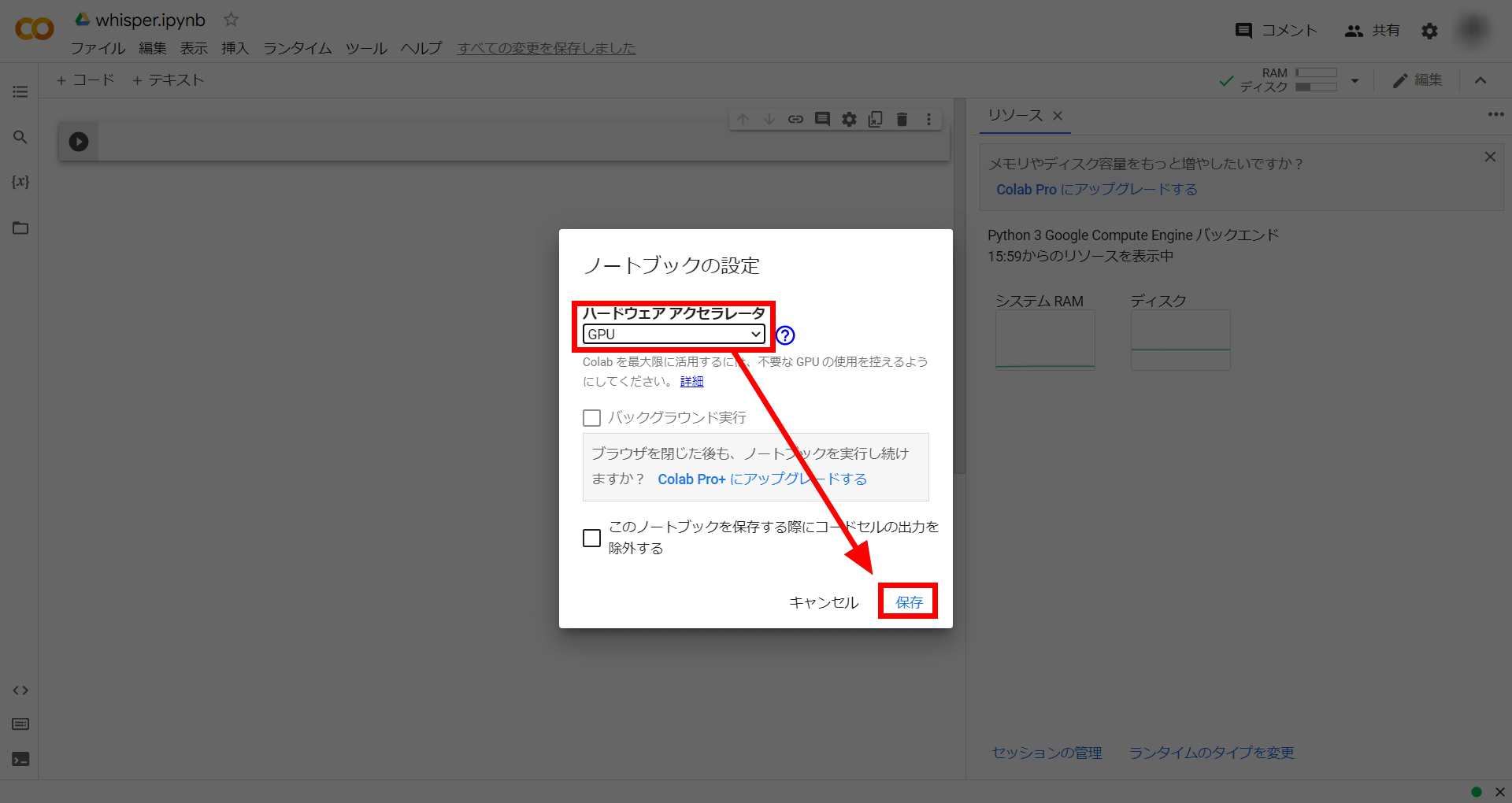
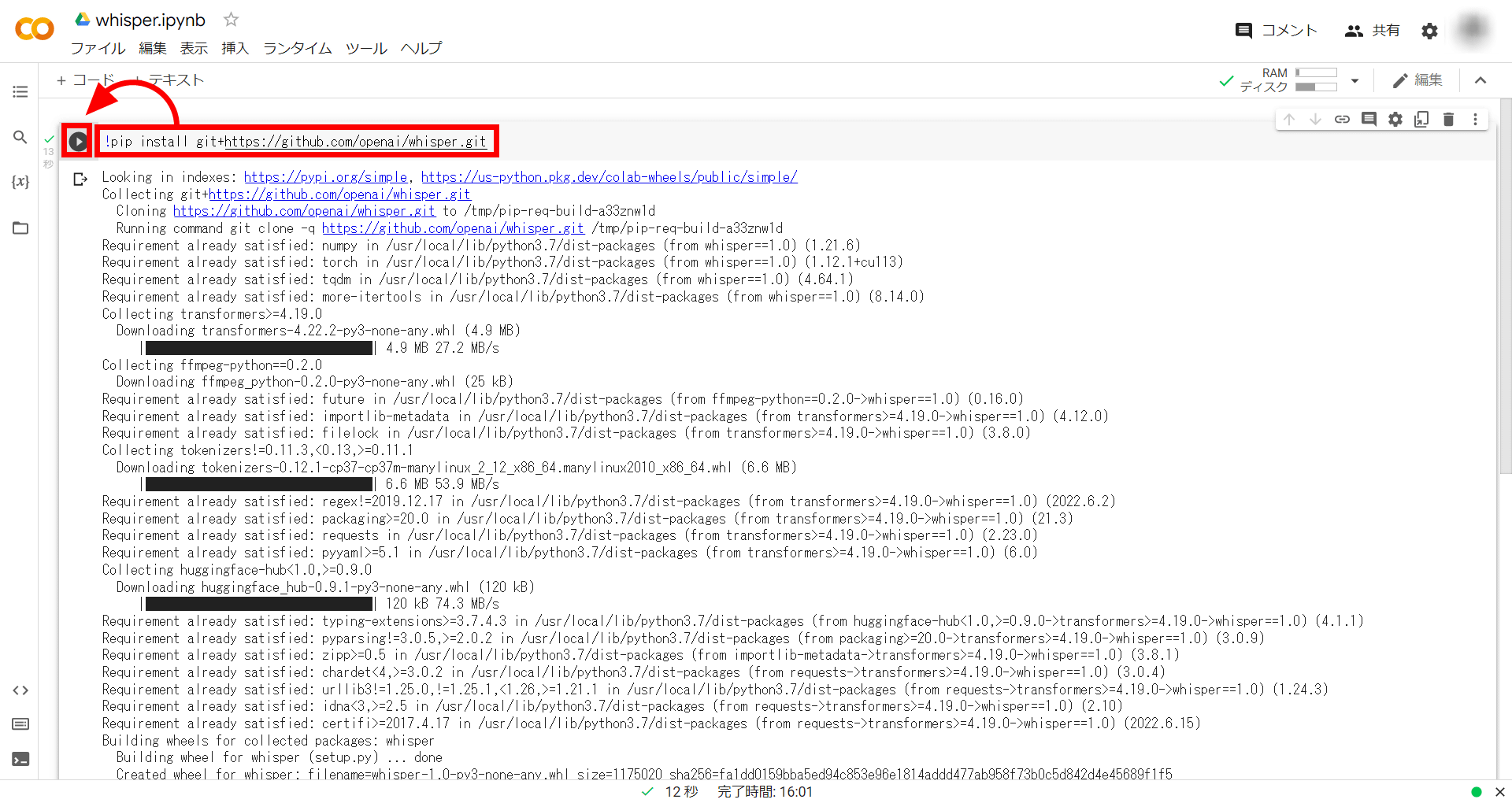
続いてコード。まずはWhisperのリポジトリをGoogle Colabにインストールするため、以下のコマンドを入力。
!pip install git+https://github.com/openai/whisper.git
コマンドを入力したら再生アイコンをクリックして実行します。
そして、以下のコマンドを入力して実行。
import whisper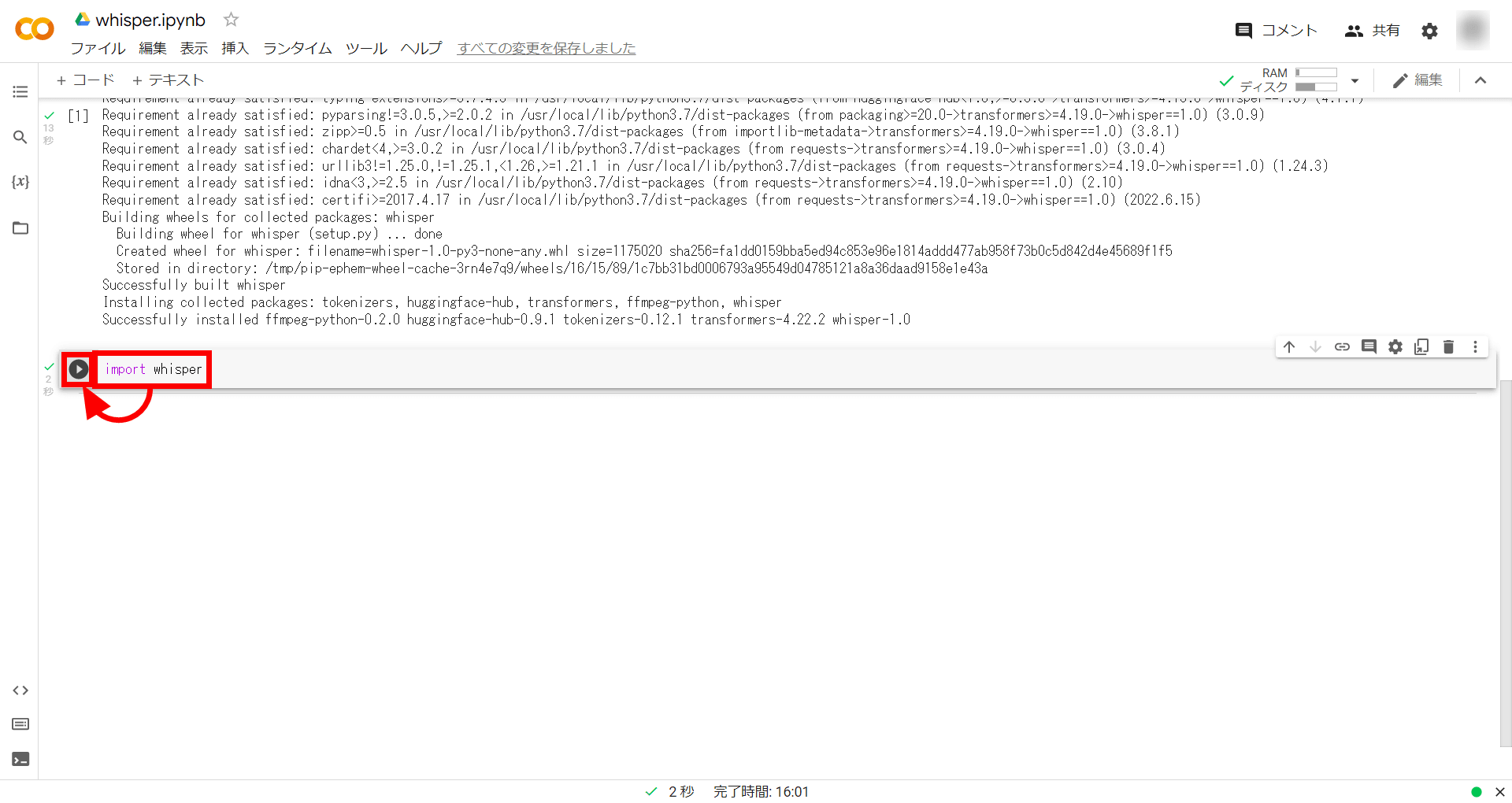
次に文字起こししたい音声ファイルをGoogle Colabにアップロードします。左端のフォルダアイコンをクリックし、「Content」フォルダの左にあるケバブアイコンをクリックします。
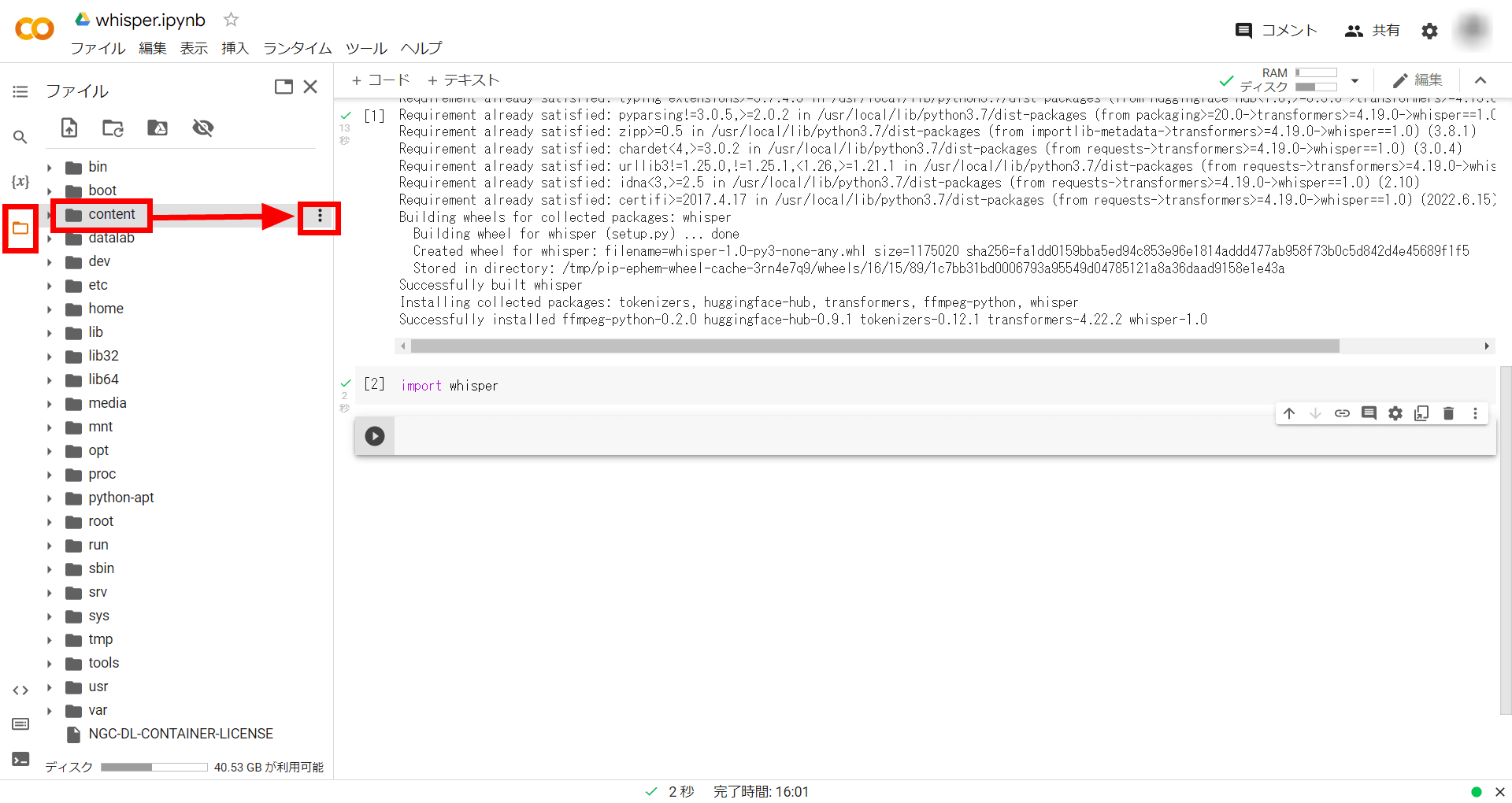
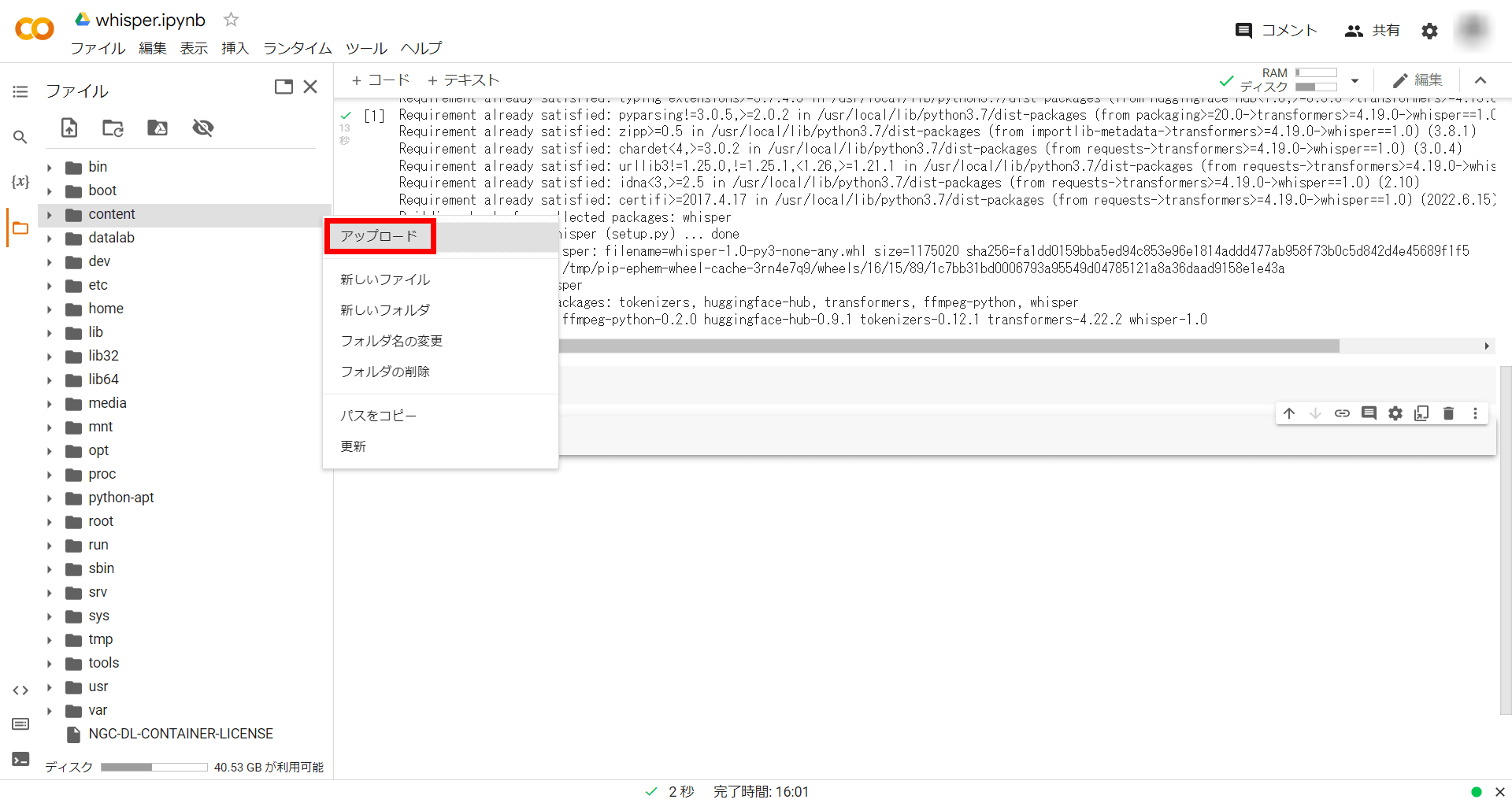
「アップロード」を選択し、アップロードするファイルを指定します。
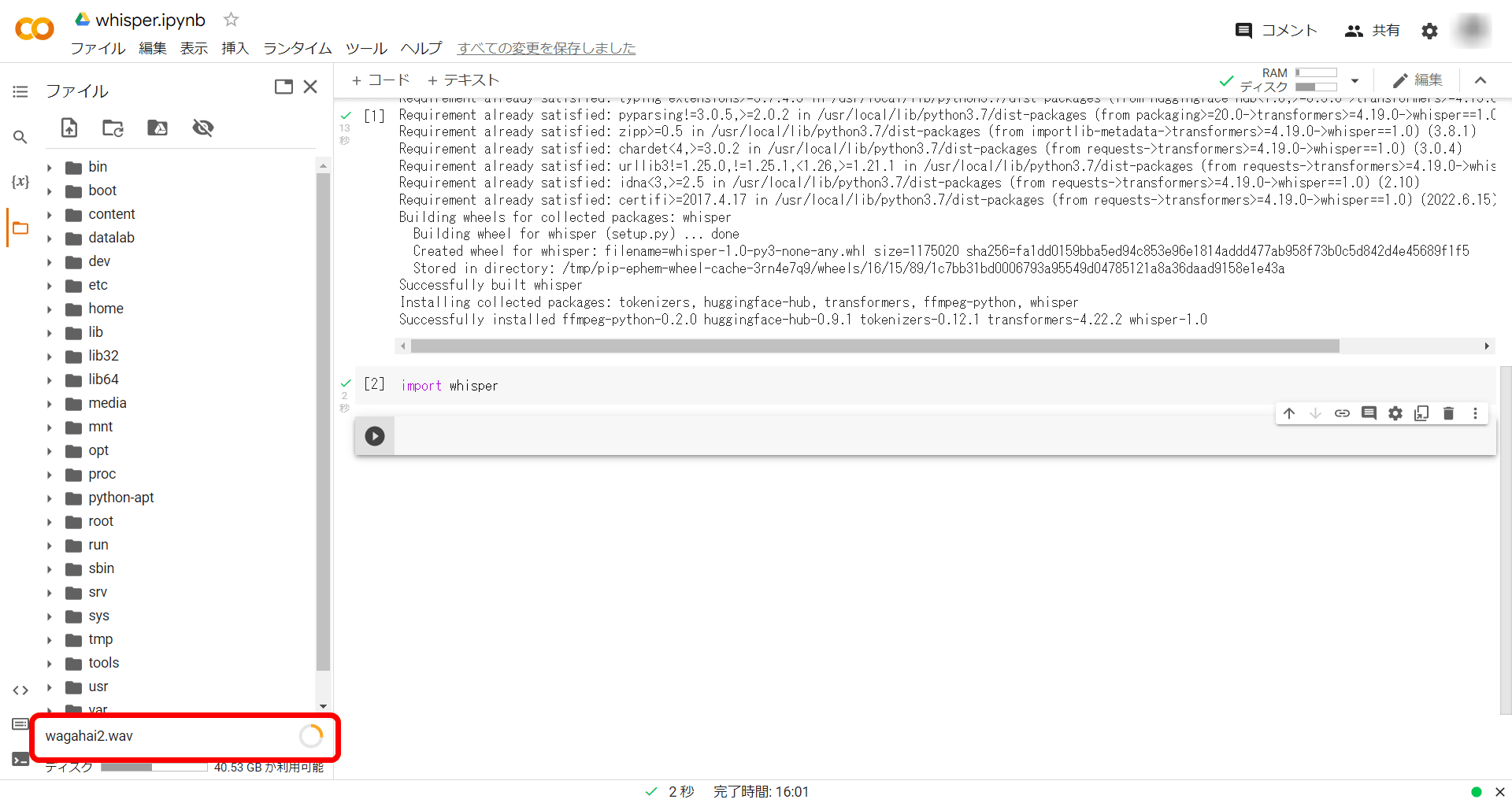
今回は「吾輩は猫である」の冒頭を読み上げて録音した「wagahai2.wav」を文字起こししてみます。
次に以下のコマンドを入力して実行します。今回はモデルに「base」を使用しています。
model = whisper.load_model("base")
result = model.transcribe("ファイル名")
print(result["text"])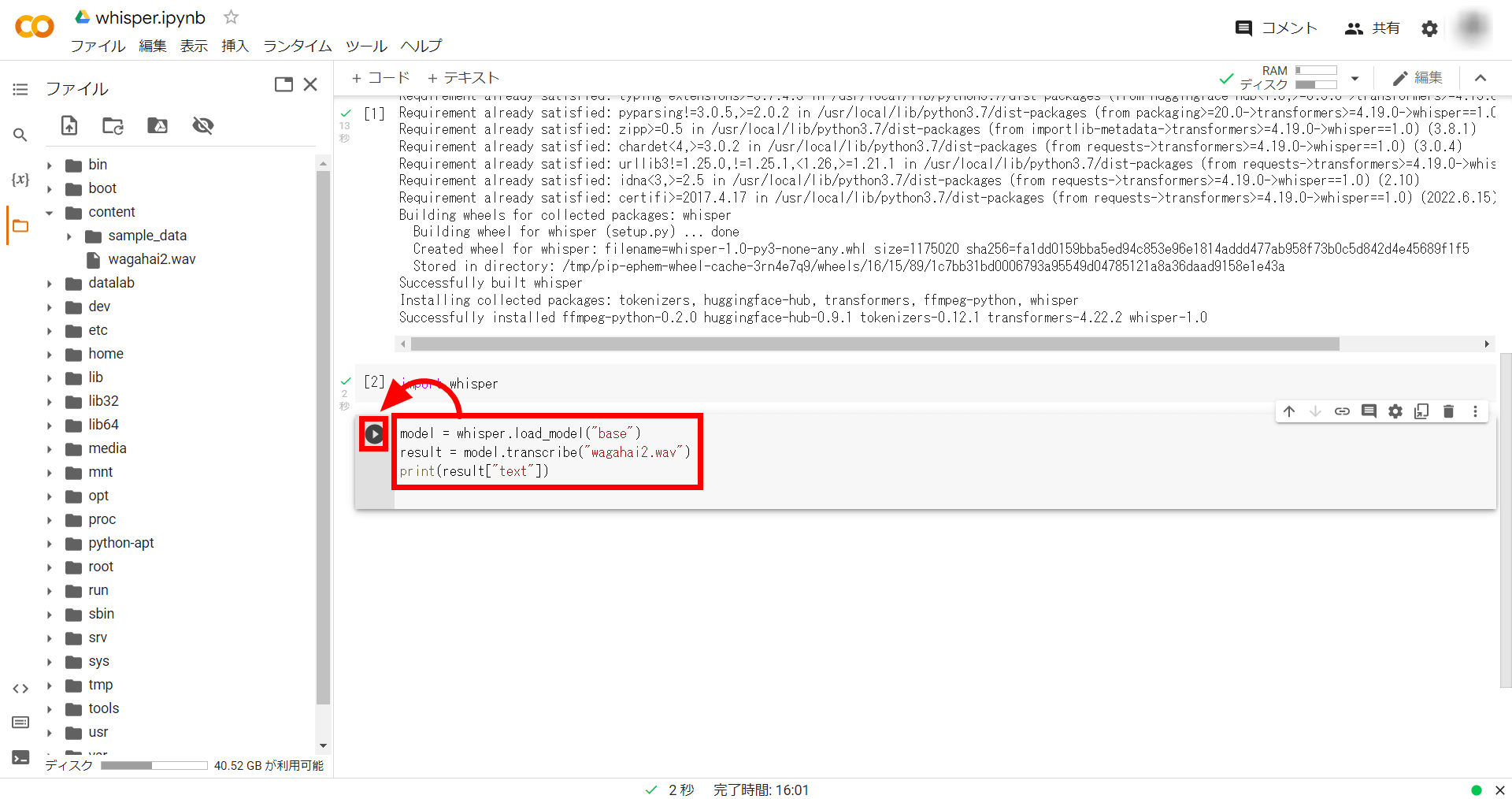
20秒ほど待つと、以下のようにテキストで文字起こしした文章が出力されました。
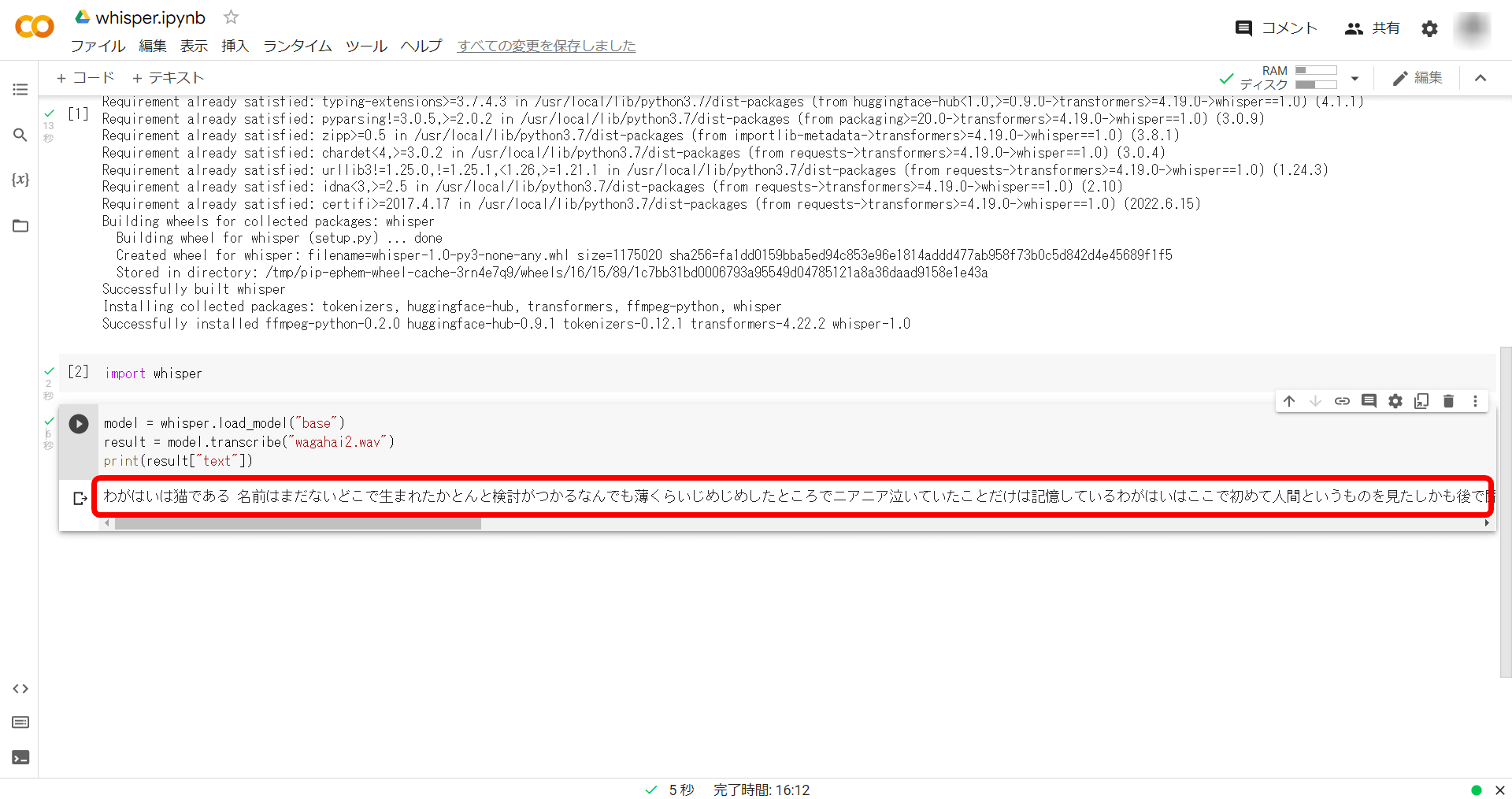
Whisperに文字起こししてもらった出力結果が以下の通り。
わがはいは猫である 名前はまだないどこで生まれたかとんと検討がつかるなんでも薄くらいじめじめしたところでニアニア泣いていたことだけは記憶しているわがはいはここで初めて人間というものを見たしかも後で聞くとそれは所成という人間中で一番同学な手作であったそうだこの所成というのは時々我々を捕まえて似てくるという話であるしかしその当時はなんという考えもなかったから別々恐ろしいとももはなかったただ彼の手のひらに乗せられてスーと持ち上げられた時何だかふわふわした感じがあったばかりである手のひらの上で少し落ち着いて所成の顔を見たのがいわゆる人間というものの見始めであろうこの時妙なものだと思った感じが今でも残っている第一 気を持って装飾されべきはずの顔がつるつるしてまるでやかんだその後猫にもだいぶあったがこんな方はにはで一度もで壊したことはない
読み上げた原文が以下。少し早口で朗読してしまったために句読点が詰まってしまっており、漢字変換にも「見当」が「検討」、「書生」が「所成」などといったミスがありました。加えて「煮て食う」が「似てくる」、「獰悪な種族」が「同学な手作」という聞き違いはあるものの、それ以外はこれといった修正ポイントが少ないので、文字起こしとしてはかなり高い精度だといえます。
吾輩は猫である。名前はまだ無い。
どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪(どうあく)な種族であったそうだ。この書生というのは時々我々を捕まえて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌(てのひら)に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始(みはじめ)であろう。この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶(やかん)だ。その後猫にもだいぶ逢ったがこんな片輪(かたわ)には一度も出会(でく)わした事がない。
◆Windows環境に導入してみる
・Pythonのインストール
Python公式サイトから最新版(記事作成時点で3.10.7)をダウンロードしてインストールします。インストール方法は以下の記事の「◆3-1:Pythonのインストール」で説明されています。

・CUDAのインストール
NVIDIAの開発者向けサイトで「CUDA Tool 11.3」をダウンロードしてインストールします。インストール方法については、以下の記事の「◆3-3:CUDAのインストール」にまとめられています。

・PyTorchのインストール
PythonのAIフレームワークであるPyTorchをインストールします。まずは以下のサイトにアクセス。
PyTorch
https://pytorch.org/
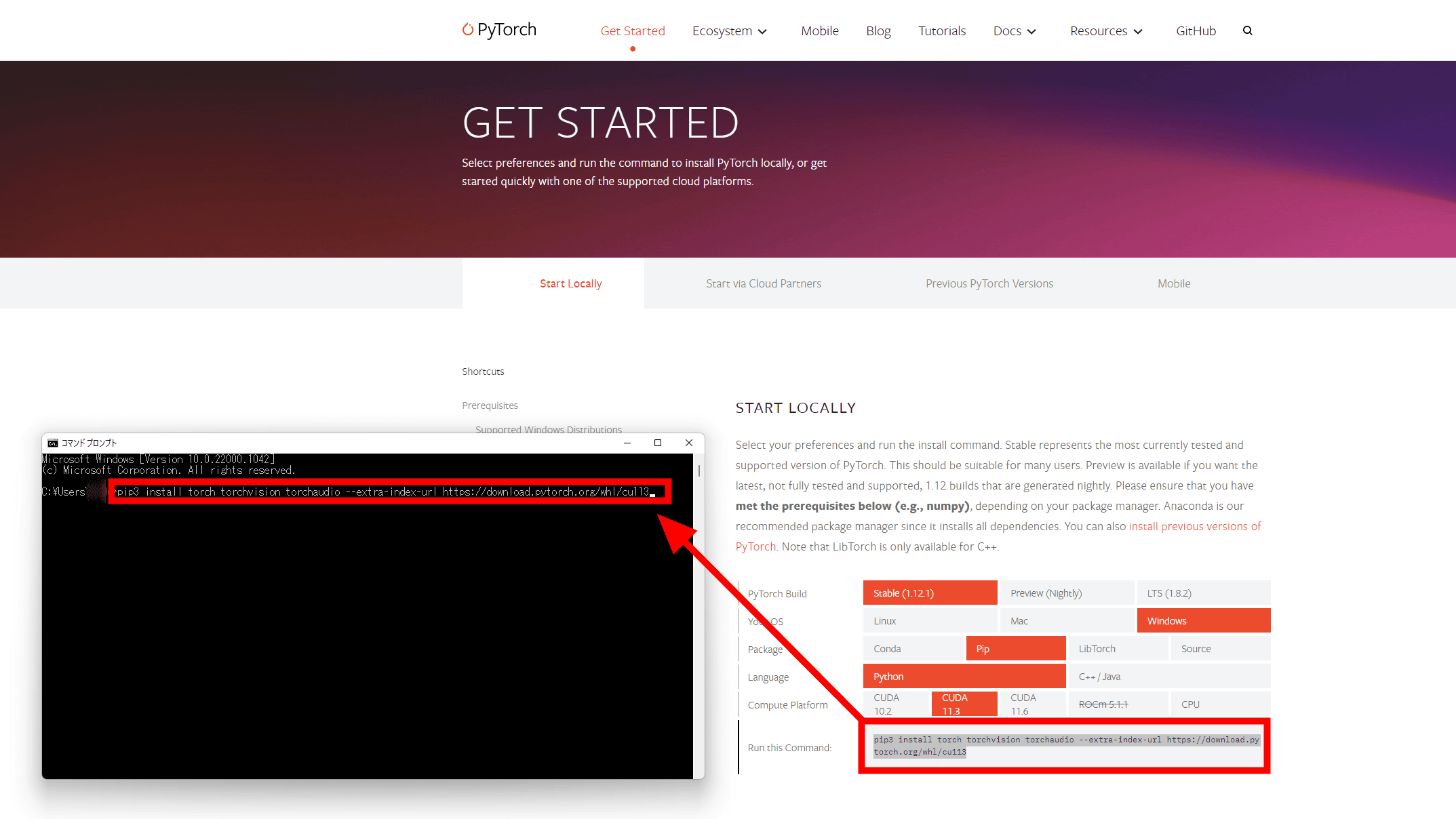
「Install」をクリック。
「START LOCALLY」で、PyTorch Buildを安定版の「Stable(1.12.1)」、OSを「Windows」、Packageはコマンドプロンプトを使うために「Pip」、Languageは「Python」、Compute Platformに「CUDA 11.3」を選択します。
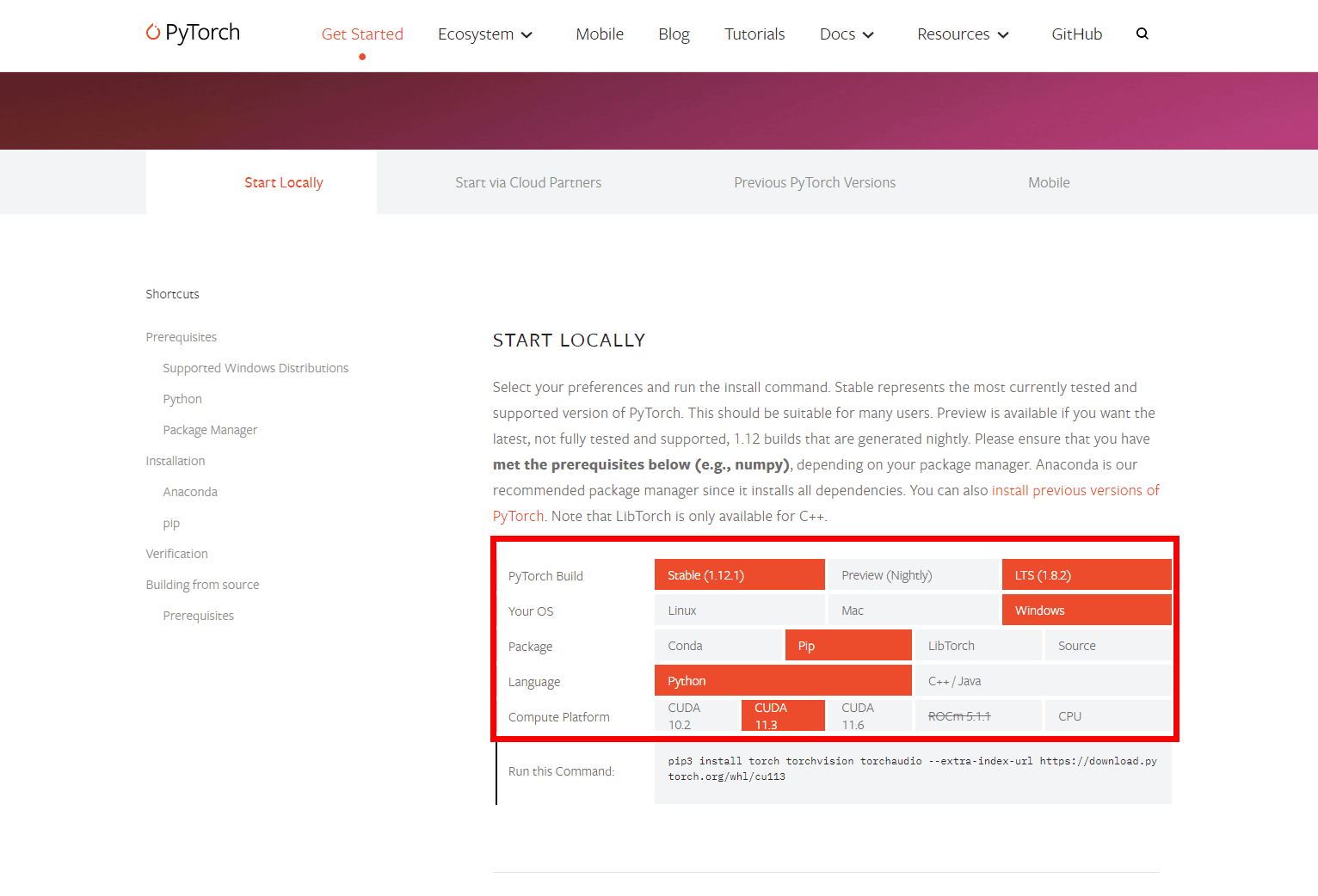
下部の「Run this Command:」に表示されたコマンドをコピーして、コマンドプロンプトで実行すれば、PyTorchをインストールできます。
・ffmpegのインストール
音声と映像を処理するffmpegをインストールします。ffmpegのインストールはパッケージ管理ソフトのChocotrayを介して行います。
Chocolatey Software | Chocolatey – The package manager for Windows
https://chocolatey.org/
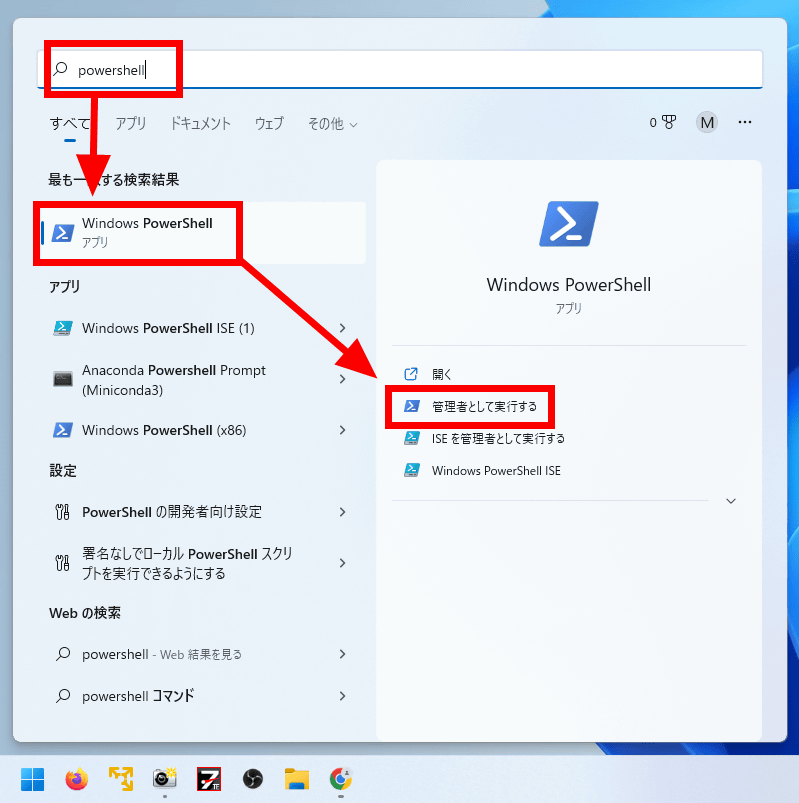
Chocotrayのインストールは、Windows PowerShellから。Windowsのスタートメニューに「powershell」と打ち込むと表示されるので、管理者として実行します。
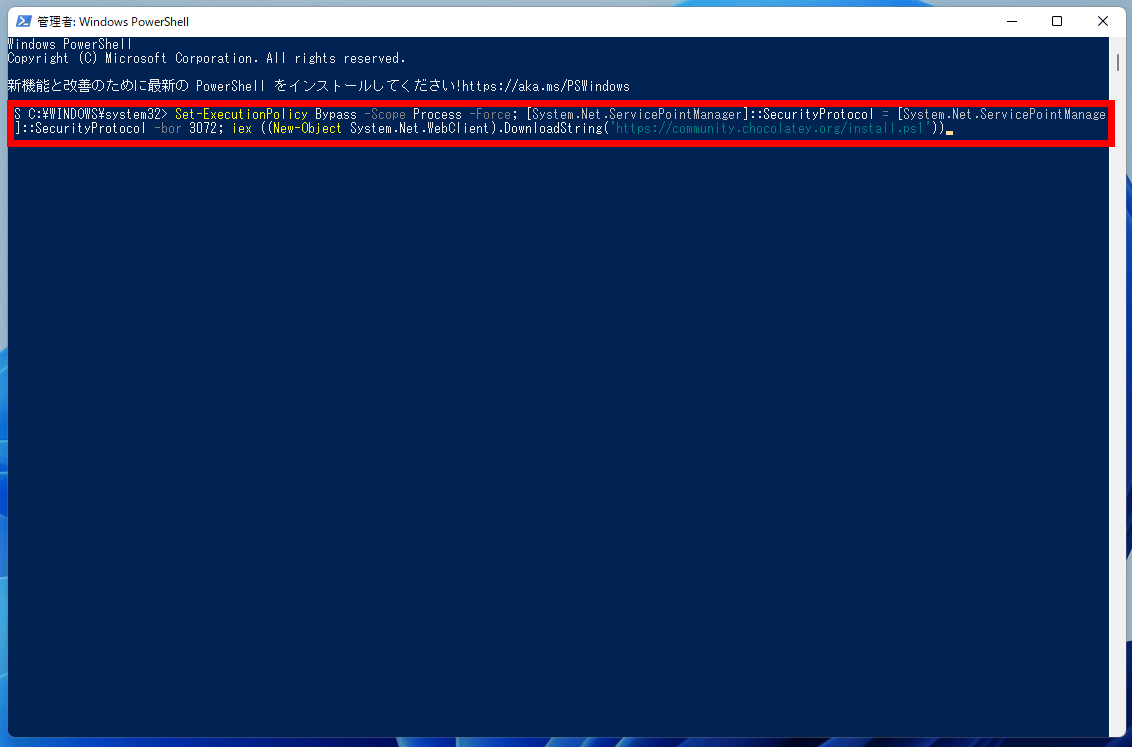
そして、Windows Powershellで以下のコマンドを入力。
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))入力するとこんな感じ。Enterキーを押して実行します。
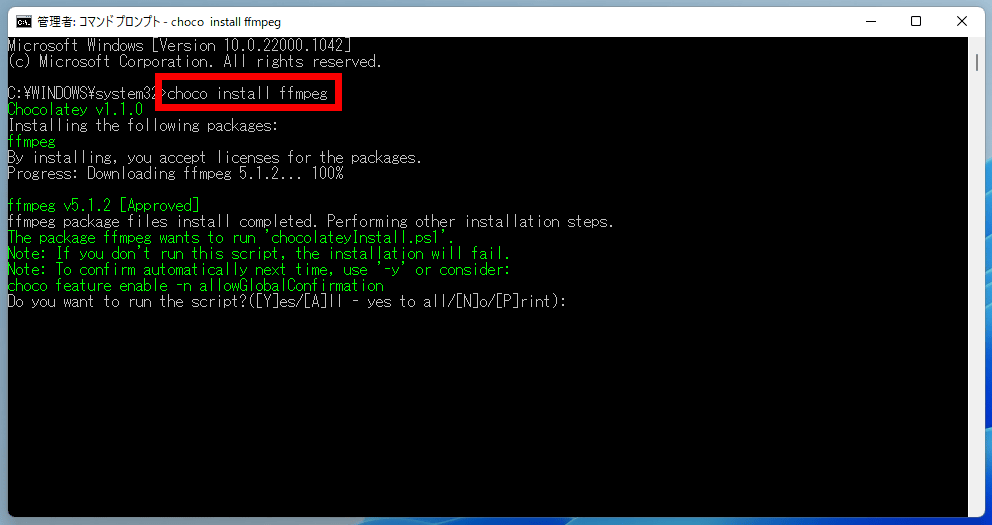
Chocotrayのインストールが終了したら、コマンドプロンプトで以下のコマンドを入力して実行。
choco install ffmpegこれでffmpegがインストールされます。
次に、Windowsの開発者モードをオンにします。Windowsの「設定」を起動します。
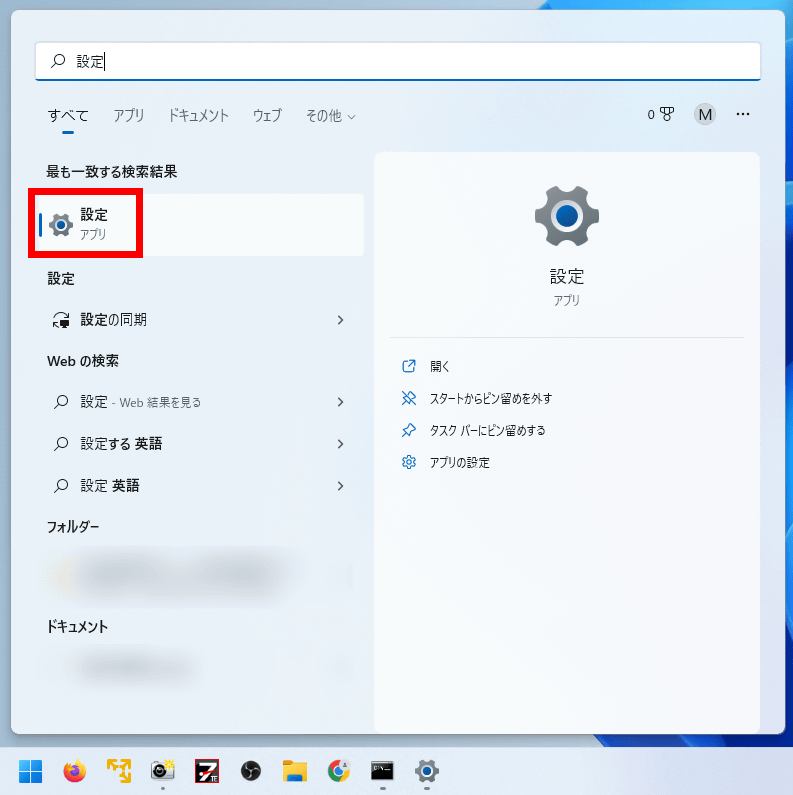
「プライバシーとセキュリティ」から「開発者向け」をクリック。
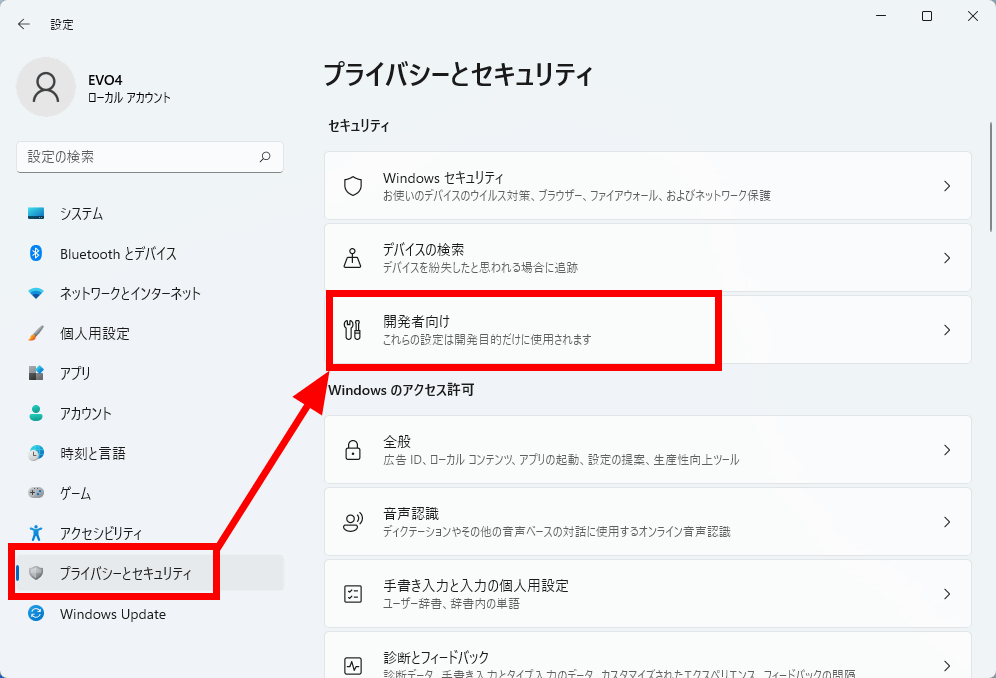
「開発者モード」のスイッチをオンに切り替えます。
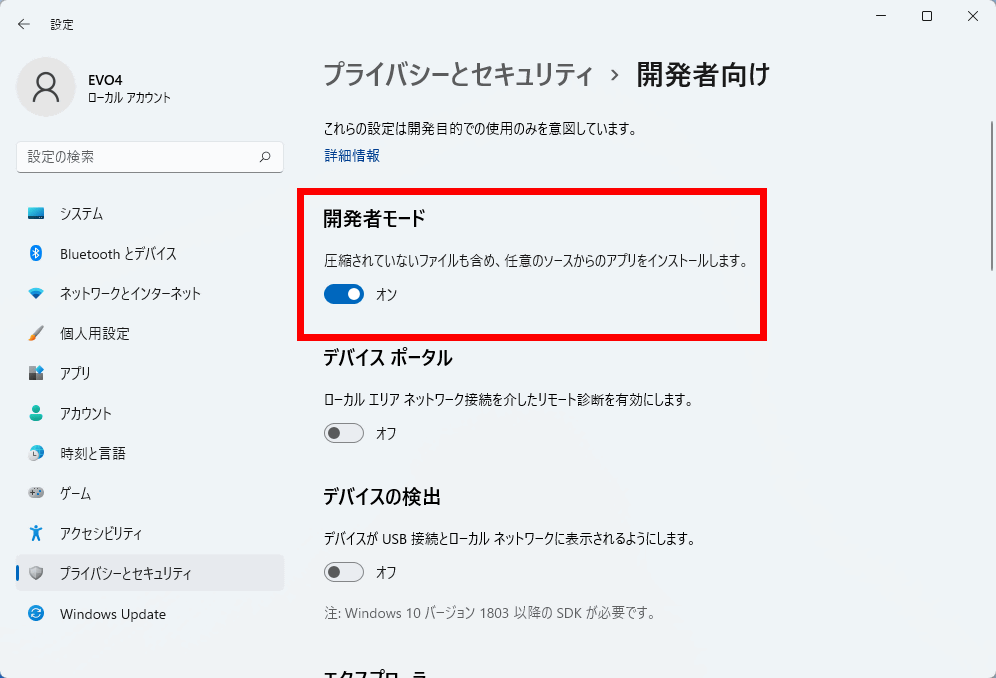
・Whisperのインストール
最後にコマンドプロンプトで以下を入力して実行します。
pip install git+https://github.com/openai/whisper.git入力するとこんな感じ
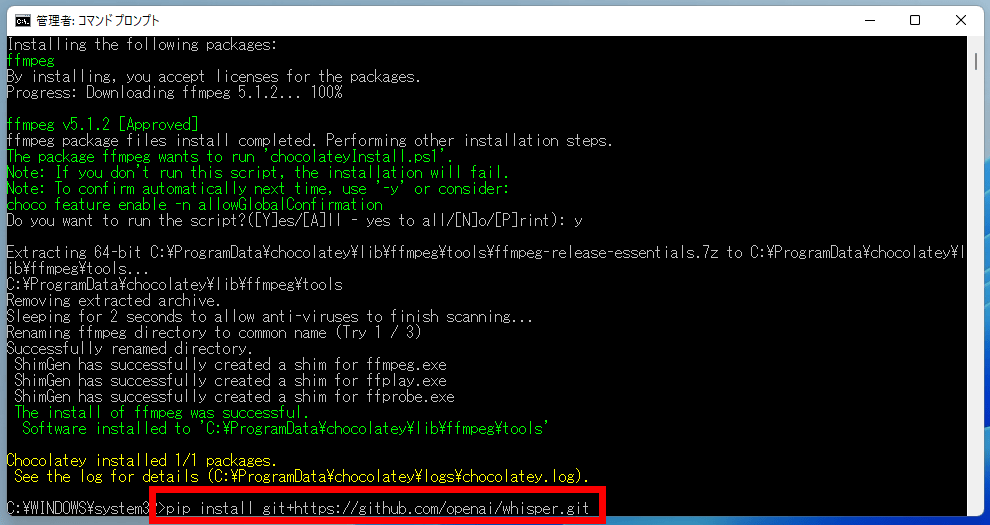
これでWhisperの導入は完了です。
◆Windowsに導入したWhisperで文字起こしをしてみる
まず文字起こししたい音声ファイルを用意します。今回はデスクトップに「whisper-sound」というフォルダを作成し、wagahai2.wavを置きました。
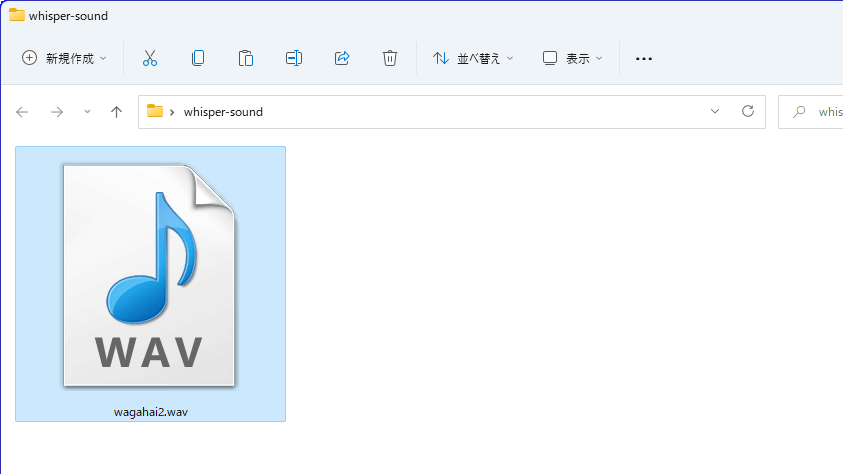
コマンドプロンプトを管理者で実行し、
cd C:\Users\(ユーザー名)\Desktop\whisper-sound
と入力し、先ほど作成したフォルダにディレクトリ移動します。そして、以下のコマンドを入力。
whipser (ファイル名) --model (モデル名) --language JapaneseGoogle Colabの時はbaseモデルで文字起こししましたが、今回はWindowsのローカル環境ということで、最大モデルであるlargeで文字起こししてみます。「whisper wagahai2.wav –model large –language Japanese」と入力して実行。
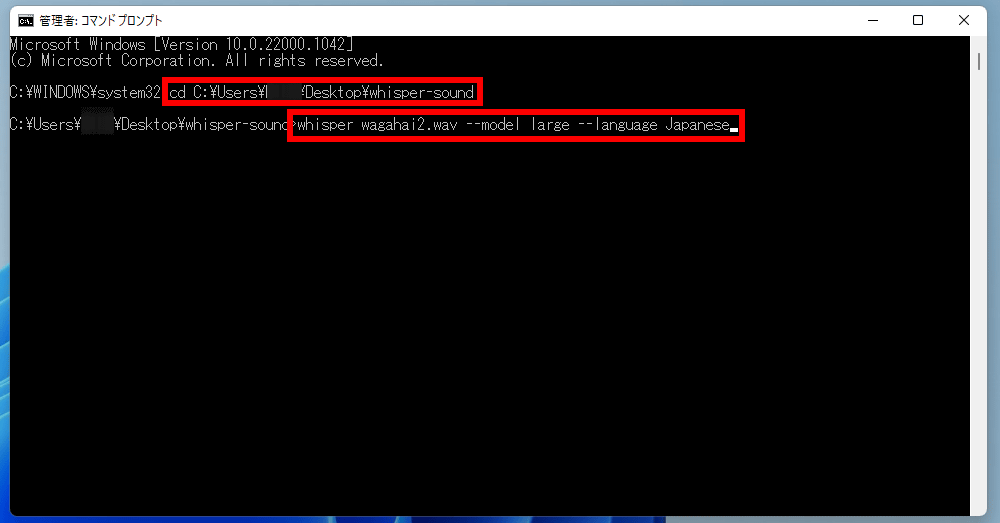
最初にモデルデータがロードされます。最も大きいモデルであるLargeは2.87GBもあります。
その後、文字起こしされた内容がコマンドプロンプトに表示されていきます。1分6秒の音源ですが、モデルのロード時間を抜けば文字起こしにかかったのは30秒~40秒ほど。
完了したら、音源と同じディレクトリに文字起こしのテキストファイルが出力されていました。
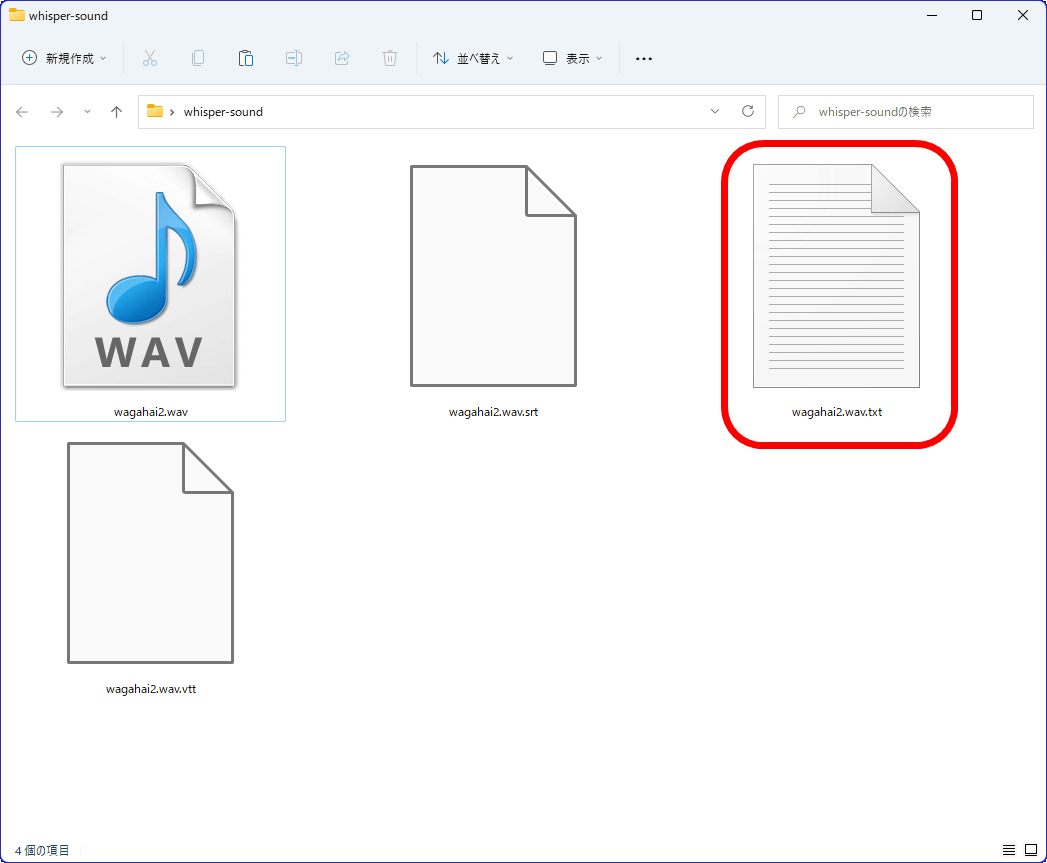
書き起こし内容は以下の通り。原文と比較すると、一部に漢字変換ミスはあるものの、手直しする部分はかなり少なくスムーズに文字起こしされており、精度も高いと感じました。largeモデルは作業負荷が大きく文字起こしの処理にも時間がかかるものの、文字起こしの精度は一番高くなっています。
我が輩は猫である。名前はまだ無い。どこで生まれたかとんと検討がつかぬ。何でも薄暗いジメジメしたところでニャーニャー泣いていたことだけは記憶している。
我が輩はここで初めて人間というものを見た。しかも後で聞くとそれは諸星という人間中で一番道悪な種族であったそうだ。この諸星というのは時々我々を捕まえて煮て食うという話である。
しかしその当時はなんという好考えもなかったから別段恐ろしいとも思わなかった。 ただ彼の手のひらに乗せられてスーッと持ち上げられた時、なんだかふわふわした感じがあったばかりである。
手のひらの上で少し落ち着いて諸星の顔を見たのがいわゆる人間というものの見始めであろう。 この時妙なものだと思った感じが今でも残っている。
最初、毛を持って消食されべきはずの顔がつるつるしてまるでやかんだ。 その後猫にもだいぶあったが、こんなかたわ庭で一度も出くわせたことがない。
なお、5つあるモデルの中でちょうど中間のサイズであるsmallモデルで、同じwagahai2.wavを文字起こしするとこんな感じ。ところどころにミスはありますが、十分日本語として読めるレベルに文字起こしされています。ただし、やはりlargeモデルと比較すると、精度は甘い印象です。
ワガハイは猫である。名前はまだない。どこで生まれたかとんと検討が使う。
何でも薄くらいジメジメしたところでにゃーにゃー泣いていたことだけは記憶している。
ワガハイはここで初めて人間というものを見た。しかも後で聞くとそれは初生という人間中で一番同悪な種族であったそうだ。
この初生というのは時々我々を捕まえて似てくという話である。しかしその当時は何という考えもなかったから別談恐ろしいと思わなかった。
ただ彼の手のひらに乗せられて数と持ち上げられた時、なんだかふわふわした感じがあったばかりである。
手のひらの上で少し落ち着いて初生の顔を見たのがいわゆる人間というものの見始めであろう。
この時妙なものだと思った感じが今でも残っている。
第一、毛を持って消色されべきはずの顔がツルツルしてまるでやかんだ。
その後猫にもだいぶあったがこんなかたわにはで一度も出くわしたことがない。
最もサイズの小さいtinyモデルで文字起こしした結果が以下。句読点などが無視されているほか、漢字変換の精度もかなり低いといえます。
我が早いはねこでやる 名前はまだない
どこで生まれたかとんと検討がつかる 何でもすぐらいじめじめしたところで
にゃんやないっていたことだけは記憶している わが早いはここで初めて人間というものを見た
しかも後で聞くとそれは初性という 人間中で一番同学の手作であったそうだ
この初性というのは時々我々をつかまえて 似てくるという話である
しかしその当時は何という 考えもなかったから別々恐ろしいとももあなかった
ただ彼の手のひらにのせいられて 数と持ち上げられた時なんだかふわふわした感じがあったばかりである
手のひらの上で少し落ち着いて初性の顔を見たのが いわゆる人間というものの見始めである
この時見ようなものだと思った 感じが今でも残っている
第一、記憶もって正式されべきはずの顔が つるつるしてまるでやかんだ
その後、猫にもだいぶあったがこんな方はには できてもできましたことはない
Whisperは文字起こしだけではなく、翻訳も可能。例えば日本語の音声を日本語に文字起こしした後に英語に翻訳するためのコマンドは以下。
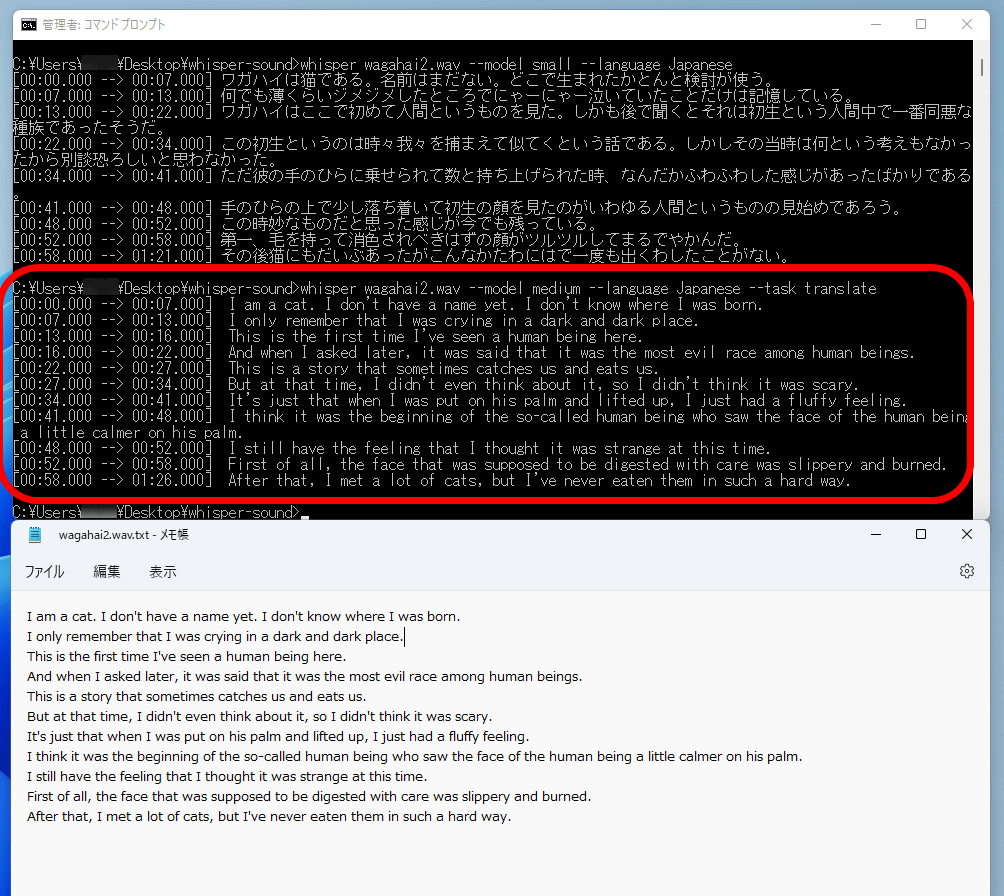
whisper (ファイル名) --model (モデル名) --language Japanese --task translate例えば「whisper wagahai2.wav –model medium –language Japanese –task translate」と入力して実行すると……
こんな感じで、日本語に文字起こしされた後に、自動で英語へ翻訳されました。出力されるテキストには英語の翻訳文のみが残っています。
この記事のタイトルとURLをコピーする