















画像生成AIのStable Diffusionは、文章を入力するだけでイラストや写真を自動で生成してくれます。しかし、この画像生成のプロセスは複雑な処理を何度も行うため、ハイスペックなGPUを搭載したマシンが必要となります。そんなStable Diffusionをスマートフォン上で、1枚2秒未満という速度で画像生成できるようにした「SnapFusion」を開発したと、ノースイースタン大学と写真共有アプリ・Snapchatの開発企業であるSnapの研究者が発表しました。
SnapFusion
https://snap-research.github.io/SnapFusion/
SnapFusionが爆速で画像を生成する様子は、以下のムービーで見ることができます。
On-Device Demo for SnapFusion – YouTube
[embedded content]
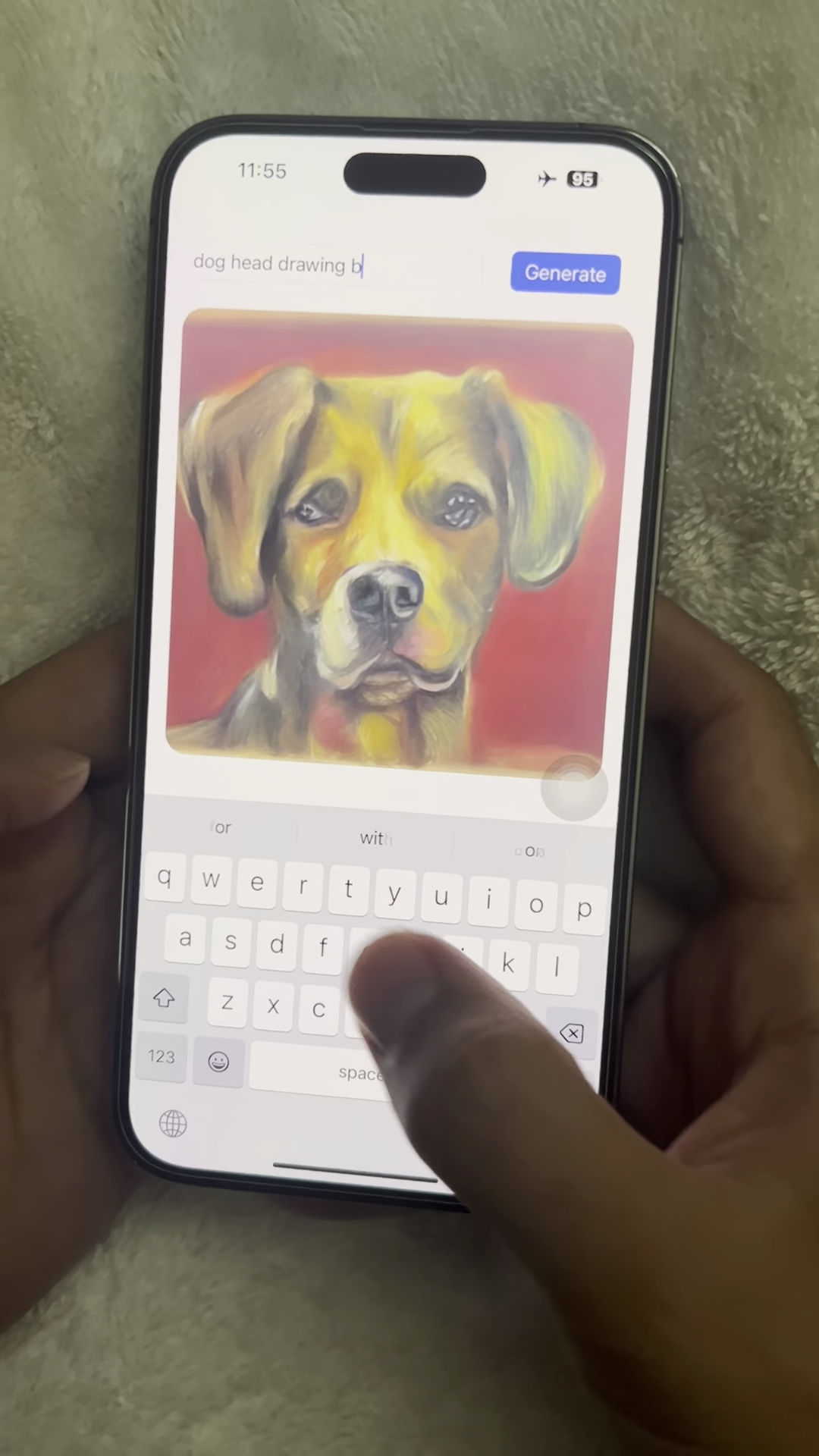
iPhoneでSnapFusionを実行しているところ。「dog head drawing(犬の頭の絵)」と入力して生成します。

サーバーへプロンプトを送信後、処理が進みます。

処理が始まって数秒で犬の絵が表示されました。

今度は「in oil painting(油絵で)」と追記して生成。

爆速で処理が進みます。
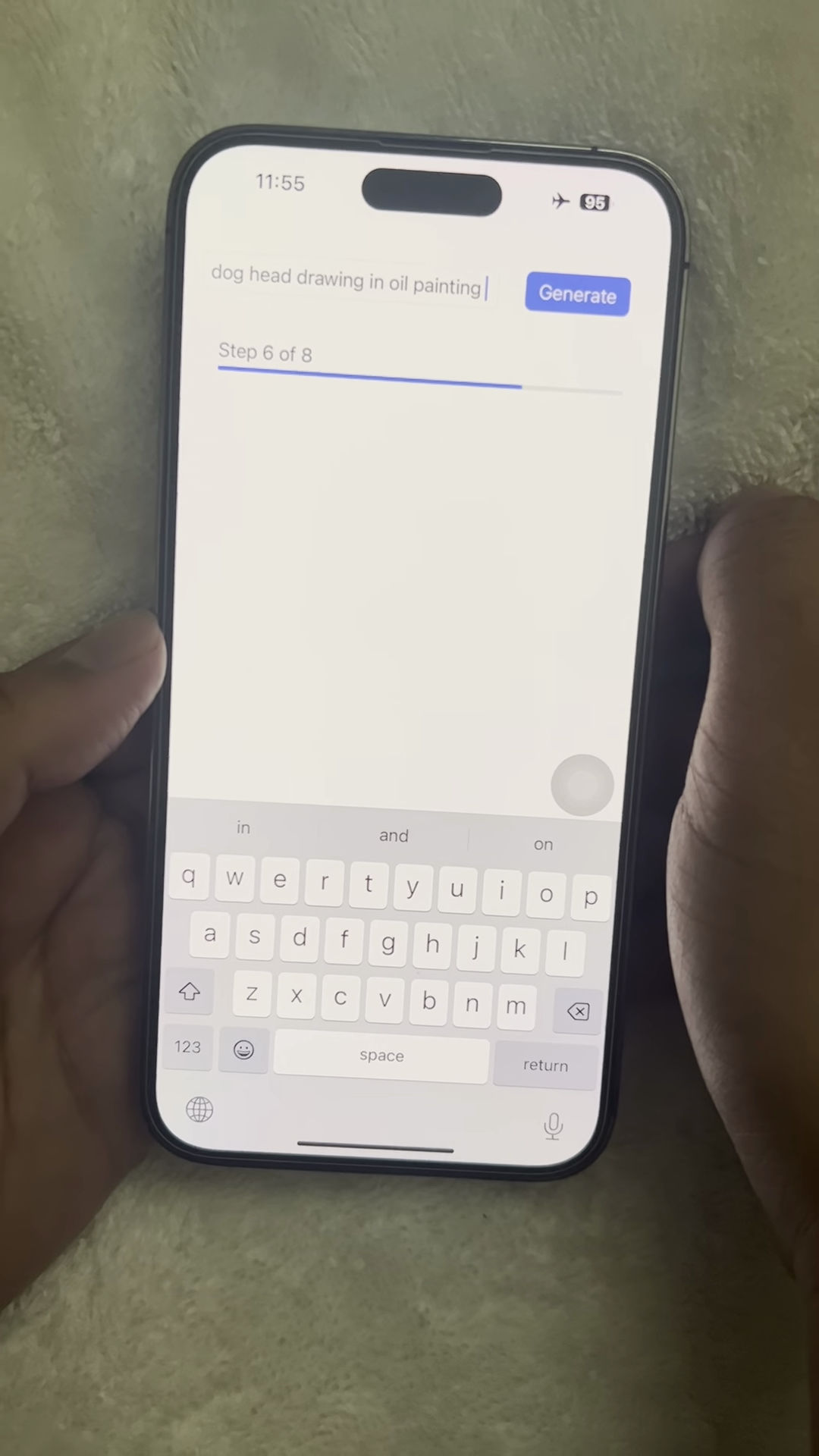
今度は犬の絵が油絵っぽいタッチで生成されました。
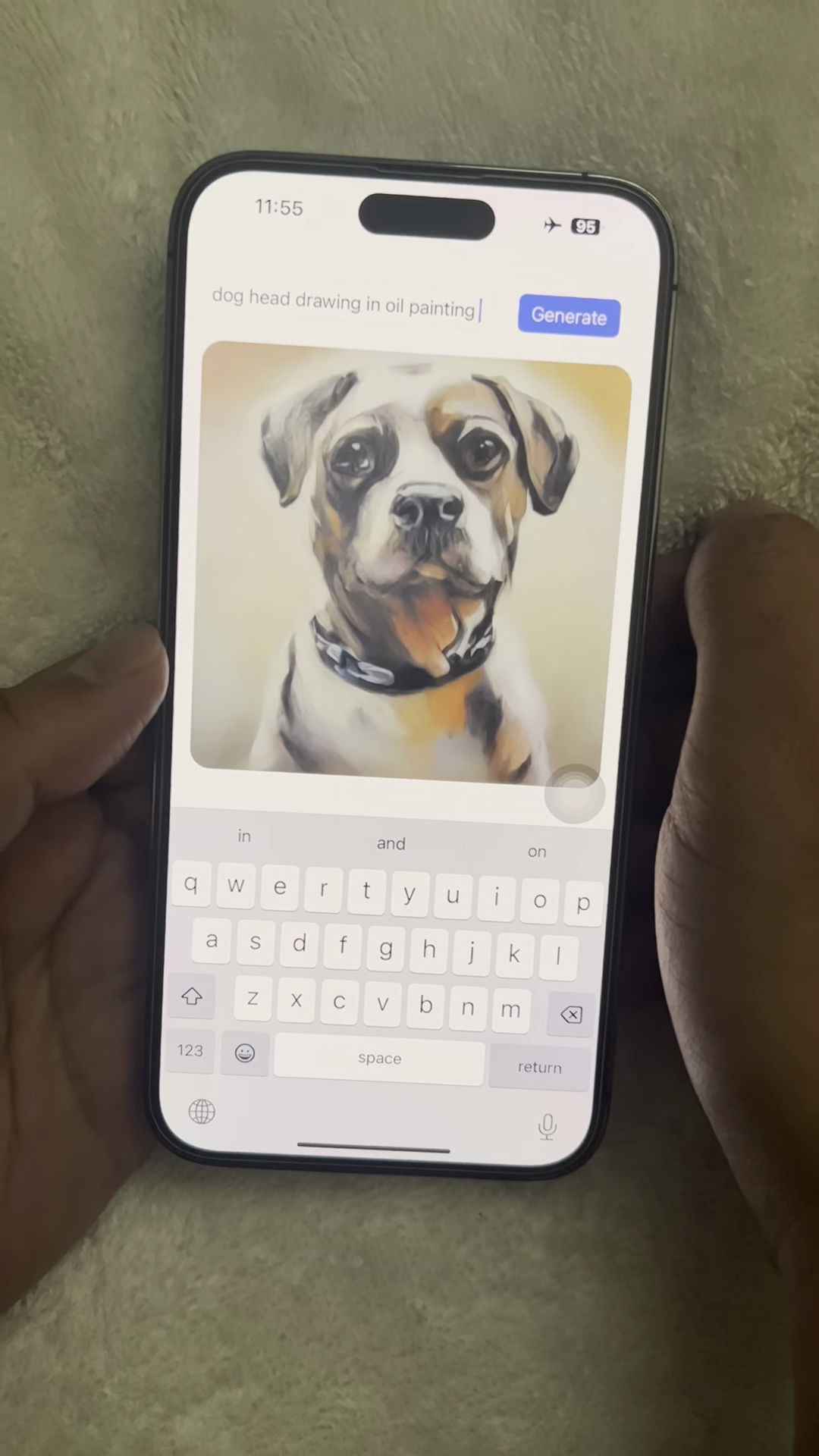
再度生成すると、シード値が変わったのか、別の犬の絵が生成されました。
研究チームは、オリジナルのStable Diffusionの冗長性を識別子、計算量を削減することで可能な、より効率的なUNetを提案しています。ムービーでは、生成のステップ数は8となっていますが、Stable Diffusionのバージョン1.5でステップ数50で生成した画像よりも応答性とプロンプトとの関連性が優れていたと研究チームは主張しています。
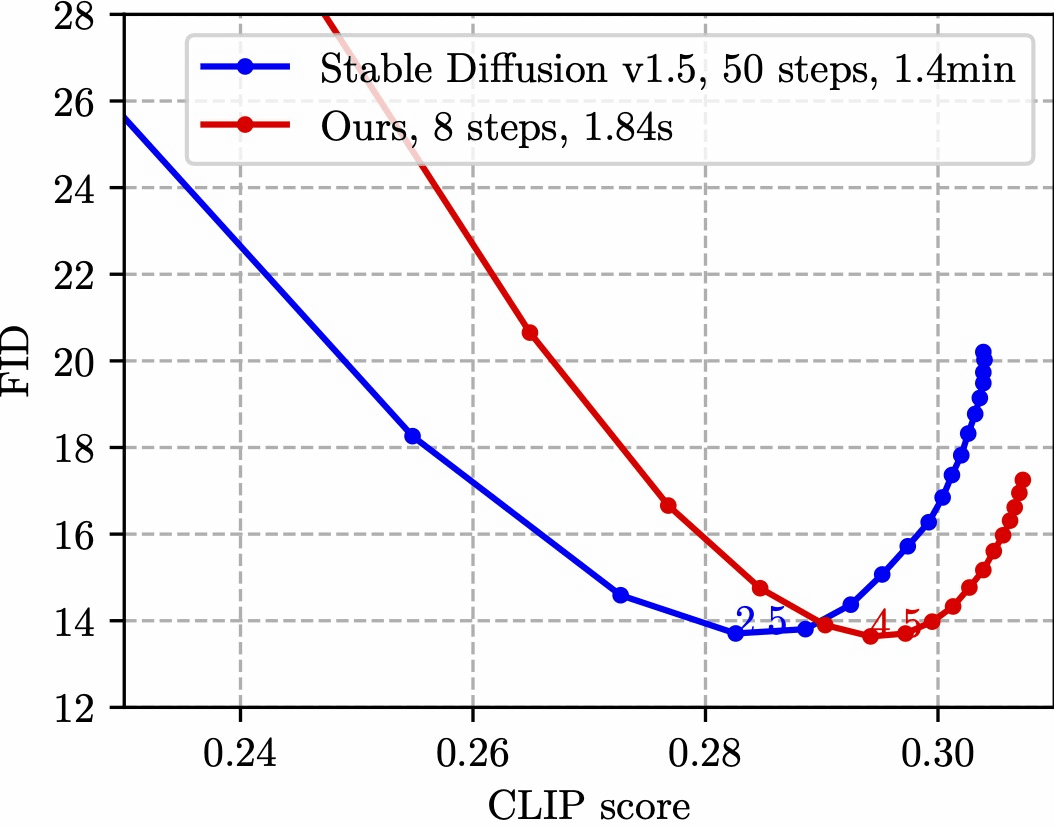
実際にSnapFusionによる8ステップ設定での生成(赤)とStable Diffusionバージョン1.5の50ステップ設定での生成(青)を比較したグラフが以下。FID(応答性)が縦軸で、プロンプトとの関連性(CLIP Score)はSnapFusionの方が高いことがわかります。Stable Diffusionバージョン1.5では、画像1枚の生成に1分24秒かかっていたのが、SnapFusionだと1.84秒しかかからなかったとのこと。
研究チームは、「テキストから画像を生成する強力な拡散モデルをユーザーにもたらすことで、コンテンツ制作を大衆化することが私たちの役目です」と述べました。
この記事のタイトルとURLをコピーする

