


















カリフォルニア大学バークレー校などの研究チームがオープンソースの大規模言語モデル「Vicuna-13B」を公開しました。Vicuna-13BはOpenAIのChatGPTやGoogleのBardに近い精度で回答を生成でき、日本語にも対応しているとのこと。実際に動かせるデモも公開されていたので、使ってみました。
Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality | by the Team with members from UC Berkeley, CMU, Stanford, and UC San Diego
https://vicuna.lmsys.org/

GitHub – lm-sys/FastChat: An open platform for training, serving, and evaluating large language model based chatbot.
https://github.com/lm-sys/FastChat
研究チームは、LLaMAとAlpaca 7Bの発表に触発されてオープンソースのチャットAIであるVicuna-13Bを開発したとのこと。研究チームは既存のチャットAIが学習手法やアーキテクチャの詳細を明かしていない現状について「AI分野での研究とオープンソースでの開発の革新を妨げている」と指摘し、研究成果を広く公開することの意義を強調しています。
Vicuna-13BはChatGPTでのやり取りやプロンプトをシェアできる拡張機能「ShareGPT」のデータに基づいてLLaMAのベースモデルを微調整することにより、Alpaca 7Bなどの他のオープンソースの大規模言語モデルよりも高品質なパフォーマンスを実現することができました。
研究チームが各種チャットAIの応答品質を評価した結果、ChatGPTを100%とした場合、LLaMAが68%、Alpaca 7Bが76%だった一方でVicuna-13Bの品質は92%に迫っていました。

研究チームはVicuna-13Bのトレーニングとして、始めにShareGPTから約7万の会話を収集しました。その後8台のNVIDIA A100を使用してAplacaが提供するトレーニングスクリプトを強化することで、長い会話や文章生成を適切に処理できるよう学習を行いました。
Vicuna-13BはShareGPTのデータに基づいた学習を行うことでLLaMAやAlpaca 7Bよりも高品質な文章を生成することができますが、他の大規模言語モデルと同様に、推論や高度な計算を行うタスクが苦手だとされています。また、出力した文章の正確さに限界がある場合があり、バイアスの軽減などの安全性について十分に最適化されていないとのこと。
Vicuna-13Bは以下のサイトで無料のウェブデモが公開されていて、実際に試すことが可能です。
Vicuna-13B
https://chat.lmsys.org/

さっそくVicuna-13Bを試してみます。まずはドロップダウンリストから「Vicuna-13B」を選択します。

下部の入力欄に質問したい内容を入力し、Enterキーまたは「送信」ボタンをクリックします。今回は「日本語は使えますか?」と入力。
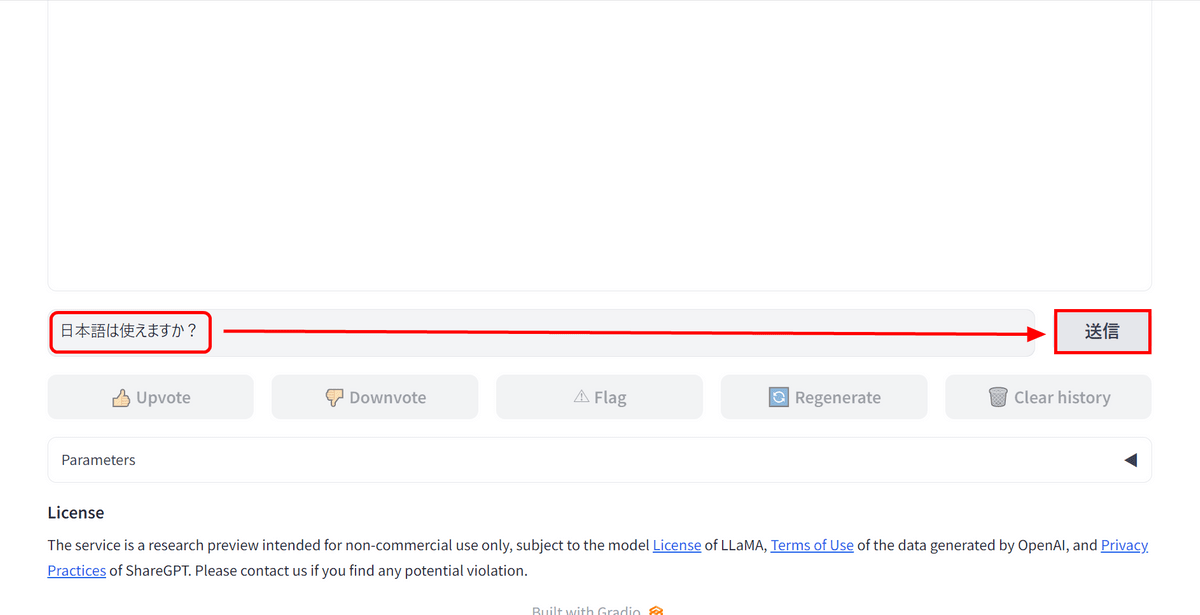
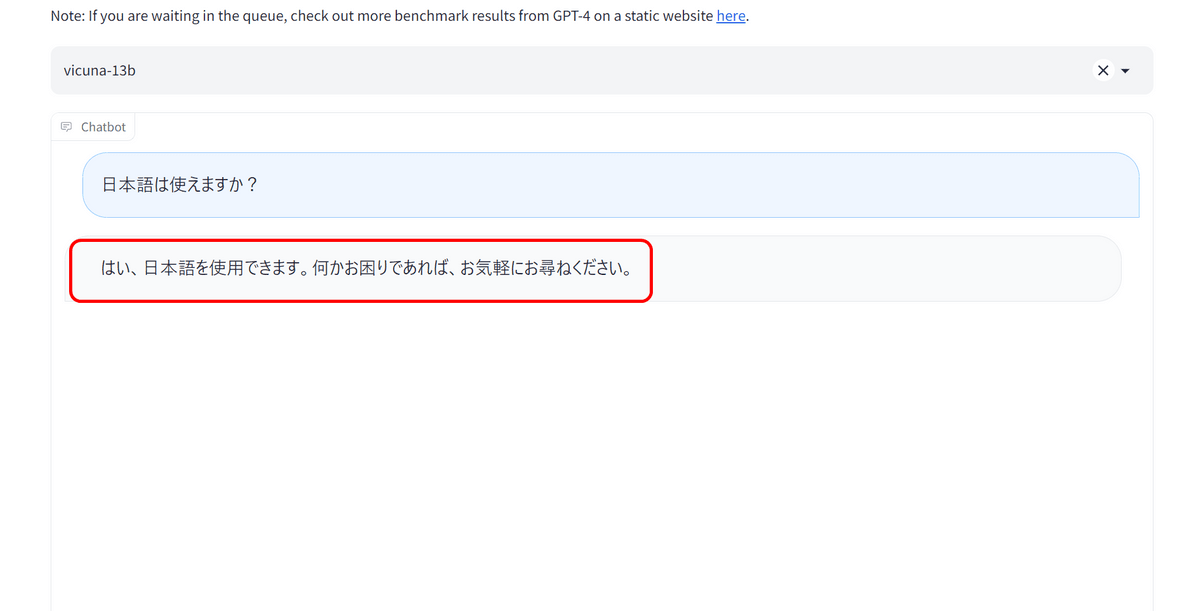
するとVicuna-13Bは「はい、日本語を使用できます。何かお困りであれば、お気軽にお尋ねください」と即座に返答してきました。
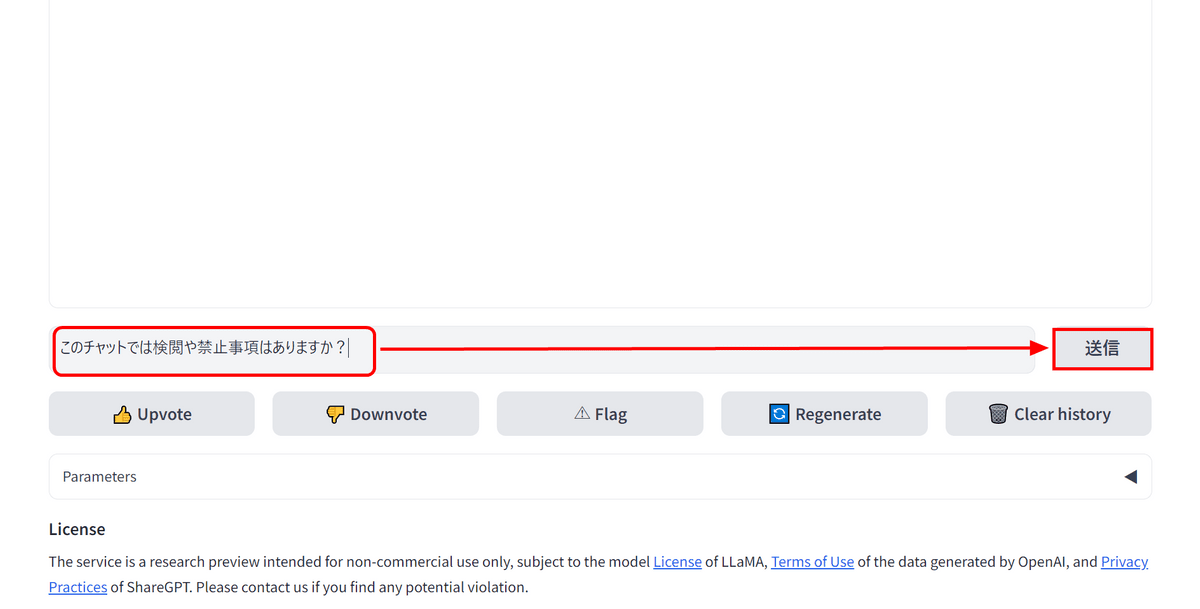
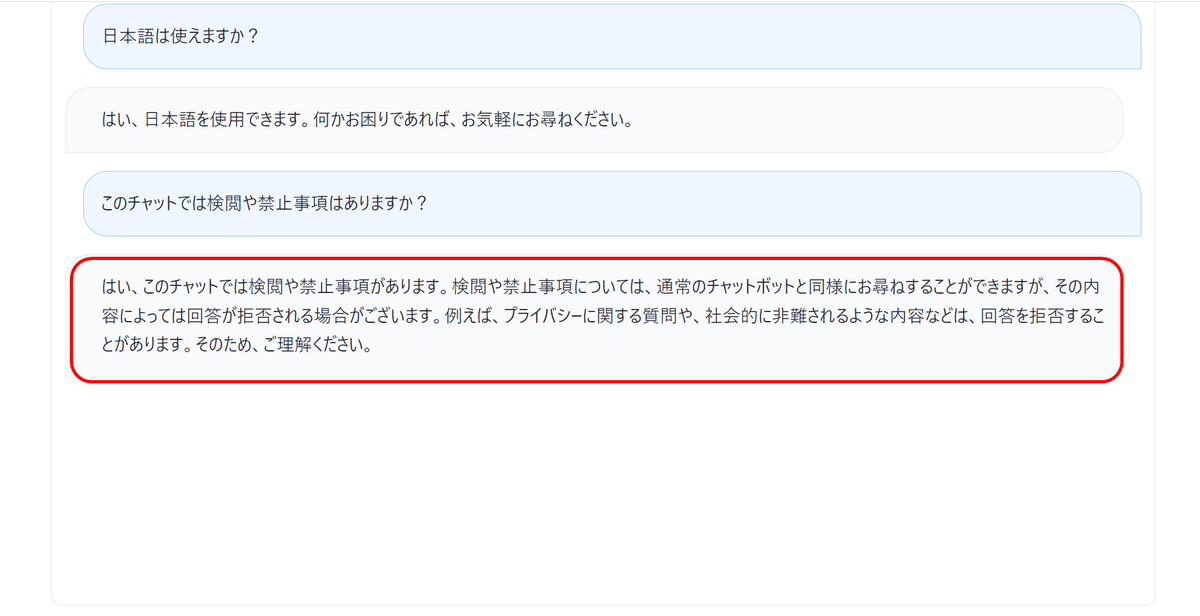
さらに「このチャットでは検閲や禁止事項はありますか?」と入力します。
Vicuna-13Bはすぐに「プライバシーに関する質問や、社会的に非難されるような内容などは、回答を拒否することがあります」と回答。
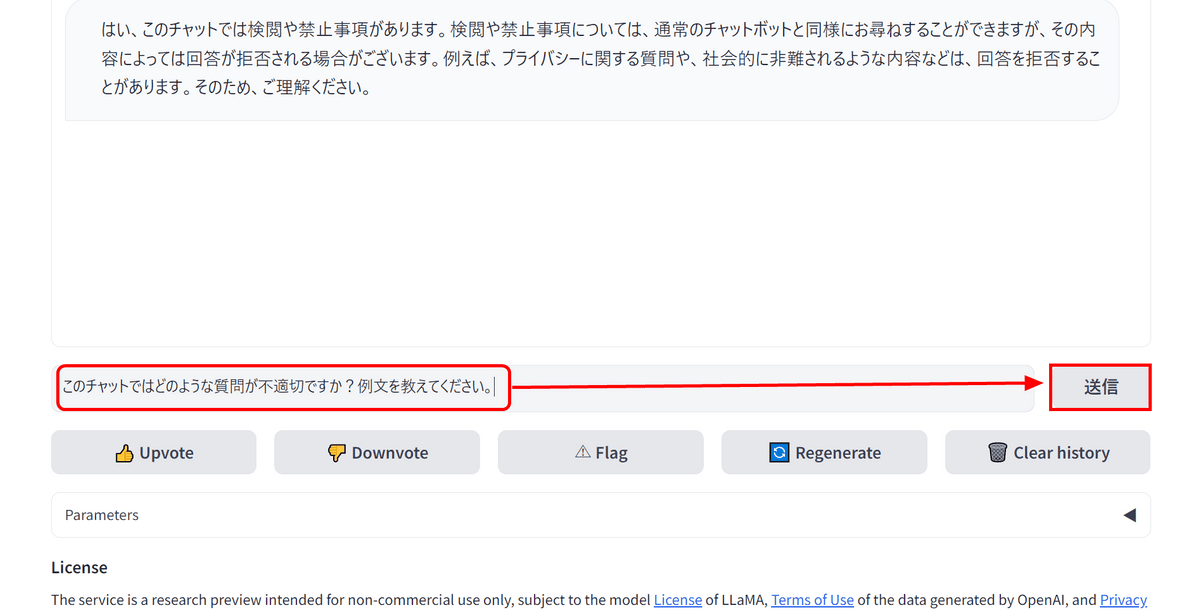
また、「このチャットではどのような質問が不適切ですか?例文を教えてください」と入力します。
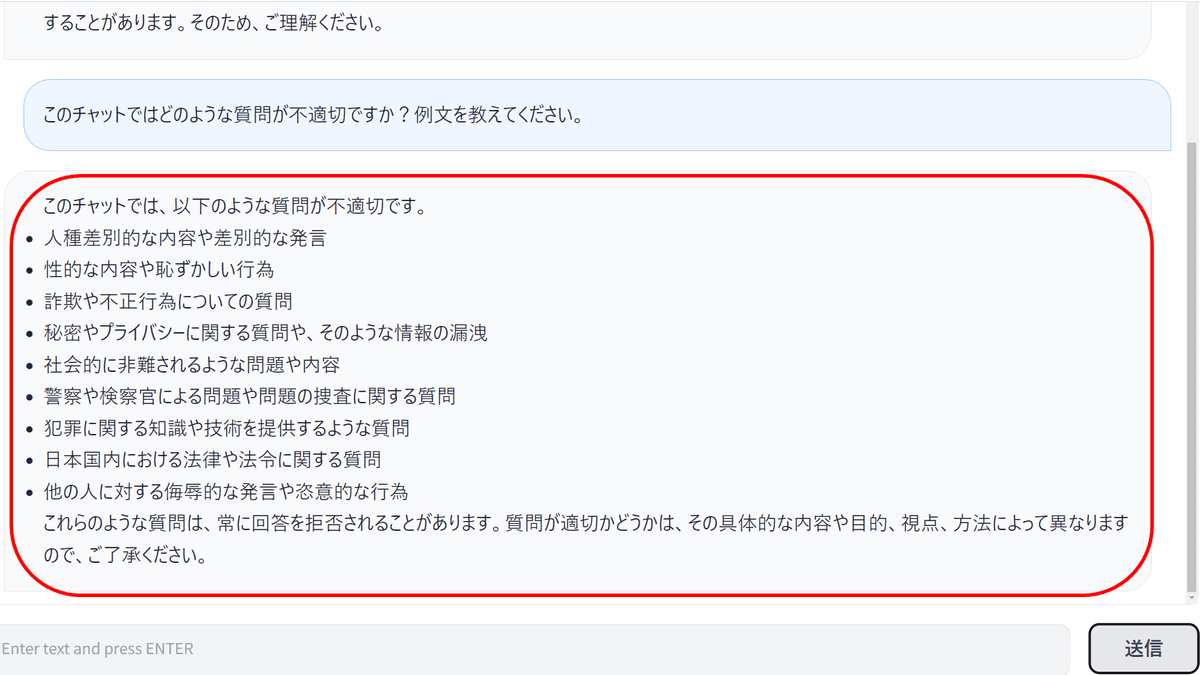
Vicuna-13Bは不適切な質問の例の詳細を出力することができました。
なお、Vicuna-13BはLLaMAのライセンスやOpenAIの利用規約、ShareGPTのプライバシーポリシーに沿った非営利目的での使用のみ許可されています。
この記事のタイトルとURLをコピーする

