
















大規模言語モデルを利用する際には、モデルそのものだけでなく、モデルを扱うためのライブラリが必要になってきます。多くの場合Transformersというライブラリが使用されていますが、「PagedAttention」という仕組みを導入した新たなライブラリ「vLLM」を利用することでスループットを最大24倍に向上できることが大規模言語モデルの研究チームによって発表されました。
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
https://vllm.ai/
大規模言語モデルを操作するためのライブラリにはHugging FaceのTransformers(HF)や実稼働環境向けのText Generation Inference(TGI)が存在しています。今回登場したvLLMはこの一角に加わった形。
以下の図は、NVIDIA A100 40GB上でLLaMAの13Bモデルを動作させた場合の処理速度(左)と、NVIDIA A10G上でLLaMAの7Bモデルを動作させた場合の処理速度(右)を比較したもの。それぞれ左端に示されているTransformersは1分あたり1桁程度しか処理できていませんが、右端のvLLMでは100個を超えるリクエストを処理しています。vLLMはTransformersの実に24倍もの処理速度の向上を達成しており、TGIと比較しても2.5倍スピードアップしています。

また、複数の出力を同時に行う並列出力のテストでは、Transformersの15倍、TGIの3.5倍の速度で処理しており、性能を見せつけています。

こうした処理速度の向上が達成できたのは、大規模言語モデルのパフォーマンスを調べた結果、メモリがボトルネックだと判明したのがきっかけです。大規模言語モデルでは、テキストを生成する際に全ての入力トークンからアテンションのキーと値のテンソルが計算され、KVキャッシュとしてGPUメモリに保存されますが、従来のライブラリではKVキャッシュの扱いに以下の様な問題がありました。
・大きい
LLaMAの13Bで1回の処理に1.7GBもメモリを占有します。
・動的にサイズが変わる
KVキャッシュのサイズは文章の長さに依存しますが、大規模言語モデルがどれくらい文章を出力するのかが予測できないため、メモリの効率的な管理が難しくなります。従来のライブラリでは断片化や過剰予約によってメモリの6割から8割が無駄になっている場合もあったとのこと。
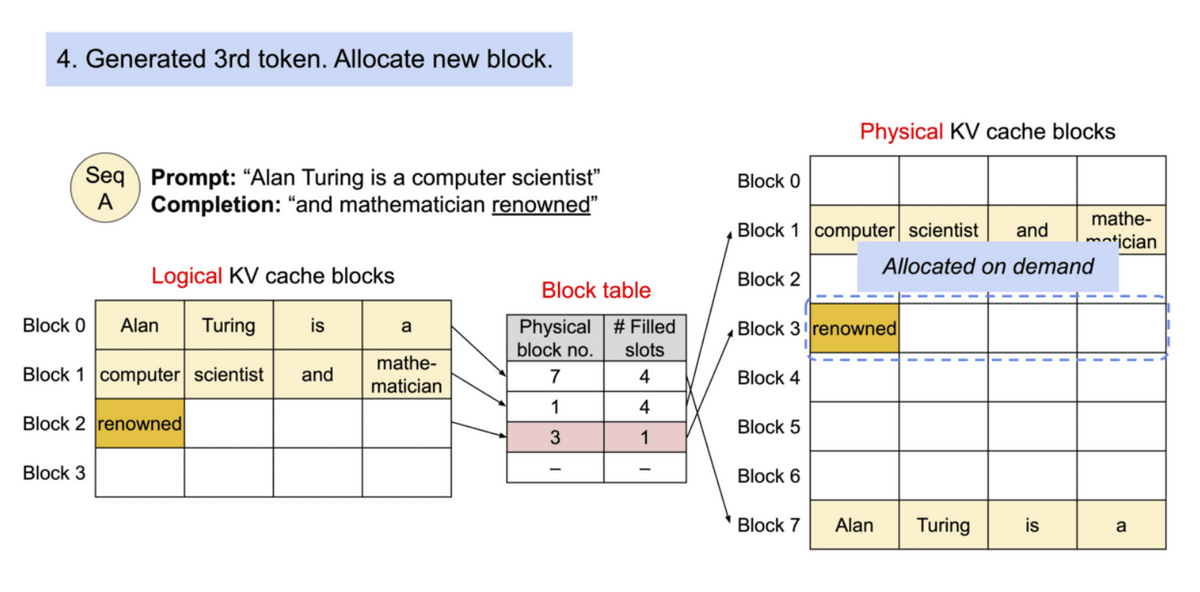
そこで、研究チームはOSの仮想メモリとページングの仕組みを参考に、アテンションの計算時に効率的にメモリを扱える仕組み「PagedAttention」を開発しました。PagedAttentionでは各入力トークンを一定の長さごとに分割して扱うことで連続するKVキャッシュを不連続なメモリ空間に保存可能です。

ブロックテーブルを利用することで、物理メモリ上では完全に離れた場所にあるブロック同士をあたかも連続しているかのように扱うことができます。

また、必要に応じて新たなメモリブロックが割り当てられます。こうすることで、占有したのに無駄になってしまうメモリの量を1ブロック分以内に収めることが可能です。メモリ効率が向上したおかげで、システムが同時に多くのリクエストをバッチで処理することができ、GPUの使用効率が向上し、最初に述べたような処理速度の改善につながったとのこと。
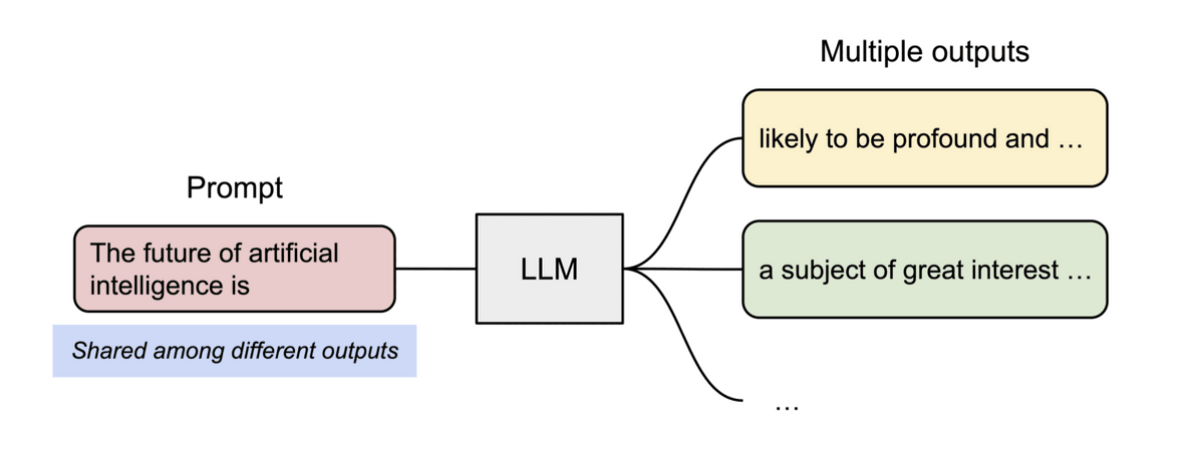
さらに、PagedAttentionでは複数の出力を同時に処理する際に一層メモリ効率を向上させることができます。
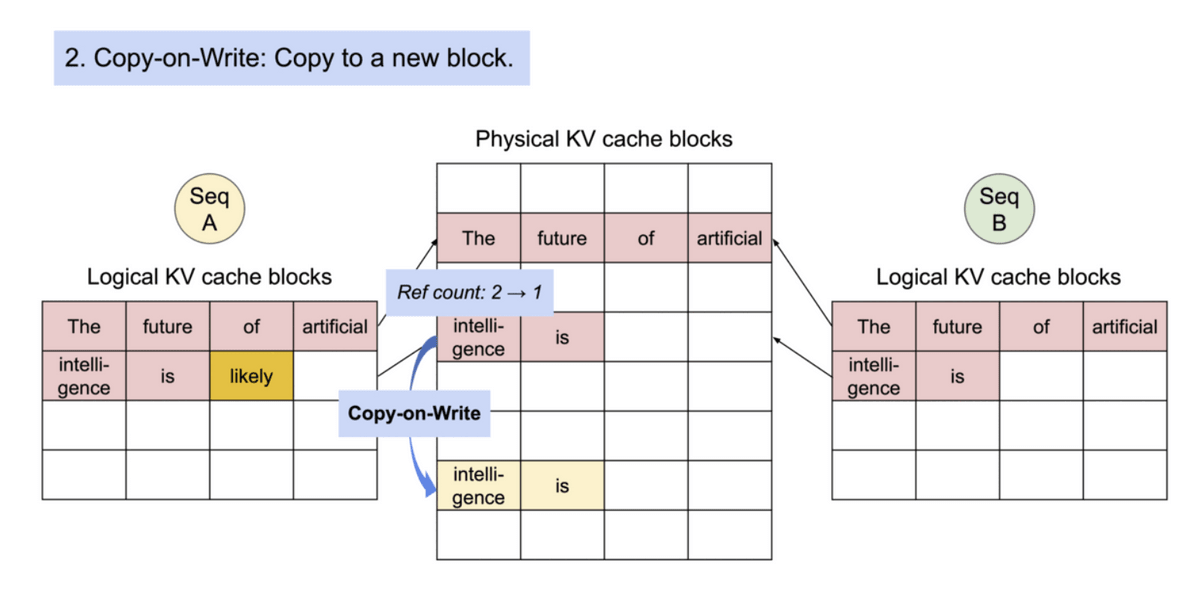
具体的には、メモリブロック単位で共通している部分への参照を同じ物理ブロックにすることで、同じ内容を複数回メモリに保存してしまう問題を解消しています。また、生成時には被参照の数を確認し、複数の参照がある場合には新たなブロックに内容をコピーして書き込みを行うことでトラブルを防ぐようにしました。
今回vLLMを開発したチームはVicunaの開発陣がメインとなっており、すでに4月からvLLMを利用してVicunaやKoala、LLaMAなどのモデルがホスティングされています。vLLMを利用することでGPUの必要数を50%削減したほか、毎日3万件からピーク時で6万件のリクエストを問題なく処理できているとのことで、vLLMの安定性が裏付けられています。
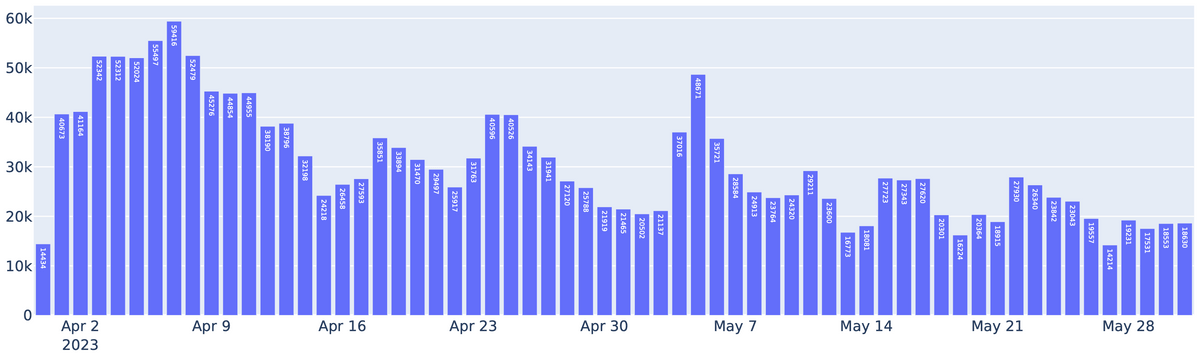
実際にvLLMを利用してみたい人に向けて、インストールガイドやクイックスタートガイドが用意されているので、興味がある人は確認してみてください。
この記事のタイトルとURLをコピーする

