

















画像生成AI「Stable Diffusion」を簡単に利用するための実行環境の1つである「Stable Diffusion web UI」のコントリビューター(開発貢献者)の1人であるAUTOMATIC1111氏が、フォークではないものの同名で「機能全部盛り」なStable Diffusion web UI(AUTOMATIC1111版)の開発を進めています。
GitHub – AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
◆目次
1:AUTOMATIC1111版Stable Diffusion web UIでできること・対応していること
2:Google Colabで動かす(NVIDIA製GPUは不要)
3:Windowsで動かす(NVIDIA製GPUが必要)
3-1:Pythonのインストール
3-2:Gitのインストール
3-3:CUDAのインストール
3-4:Stable Diffusion web UIのインストールと実行
◆1:AUTOMATIC1111版Stable Diffusion web UIでできること・対応していること
この「AUTOMATIC1111版Stable Diffusion web UI」でできることや対応していることは以下の通り。標準的な機能はすべて取り込んでいるのが特徴です。
・Outpainting:背景拡張
・Inpainting:特定の部分の描き直し
・Prompt matrix:特定のプロンプトの有無による差がわかる比較画像の作成
・Stable Diffusion upscale:最も良い結果を得られる512×512からきれいに拡大するRealESRGANを適用する「txt2imghd」の実装
・Attention:プロンプトで特に強調したい部分を()で、弱めたい部分を[]で囲い指定できる
・Loopback:「img2img」でベース画像から作成した画像をさらにベースにして作成という繰り返しを自動実行して絵のクオリティを向上させる
・X/Y plot:パラメーターの数値を変更するとどうなるのかという比較画像を作成
・Textual Inversion:自分で用意した学習データをもとにした絵柄で画像生成
・Resizing:複雑な条件でのリサイズ
・Sampling method selection:サンプリングアルゴリズムの選択(絵柄の変更)
・Interrupt:画像生成途中での停止
・4GB videocard support:512×512をビデオメモリ4GBの環境でも生成
・GFPGAN:左右非対称になりがちな顔を自然な顔にする
・Saving:特定のフォルダーを指定して保存&生成条件をCSVファイルで出力
・Correct seeds for batches:構図などを指定する要素の「シード値」を1ずつずらす
・Loading:ちょっとでも早くするためローディングをカット
・Prompt validation:プロンプトが長すぎる場合に警告
・Png info:プロンプトやパラメーターをPNG画像に埋め込む
・User scripts:ユーザースクリプトで変更や拡張が可能
◆2:Google Colabで動かす(NVIDIA製GPUは不要)
「Stable Diffusion」を動かすにはNVIDIA製GPUが必要ですが、すべてのPCにNVIDIA製GPUが搭載されているわけではありません。しかし「Google Colab」でAUTOMATIC1111版Stable Diffusion web UIを動かすことで、どんな環境でも「Stable Diffusion」を利用することができます。
まずはGoogleアカウントにログインして、以下のページにアクセスします。
StableDiffusionUI-Voldemort.ipynb – Colaboratory
https://colab.research.google.com/drive/1Iy-xW9t1-OQWhb0hNxueGij8phCyluOh
するとこのように、すでに書き込まれたページが表示されます。

それぞれ行頭にマウスカーソルを合わせると再生ボタンが表示されるので、順次この再生ボタンを押していけばOK。

最初の再生ボタンを押すとこのようなダイアログが表示されますが「このまま実行」をクリック。

すると、コードの下にずらずらと実行内容が表示されます。再生ボタンの左側に緑色のチェックマークが表示されたら、コード実行は完了なので、次のコードを実行していきます。

「import os」というコードのところでは再生ボタンを押すとブラウザ下部にセッションがクラッシュし再起動した旨のダイアログが表示され、再生ボタンが赤くなります。完了印も表示されませんが、ここはコメントで「#This will crash Colab」とあるように想定内の挙動なので、「不明な理由により、セッションがクラッシュしました。」というダイアログが出たら、閉じて次に進んでOKです。

「!pip install -r requirements.txt」のところでは「Stable Diffusion」と「Taming Transformer」という2つのGitのインストールがあるためちょっと時間がかかります。

「tensorboard」のインストールでエラーが出ましたが、特に気にしなくても問題なさそう。「RESTART RUNTIME」のボタンを押す必要はなくて、完了印が出たら次へ進みます。

作業が必要になるのはこの次で、右側に「ここにtextを挿入」という入力欄が出現します。ここにはAI関連コミュニティサイト「Hugging Face」のトークンを入力する必要があります。

トークン発行にはHugging Faceのアカウントが必要です。アカウント作成とトークン発行のやり方は以下の記事を参照してください。
画像生成AI「Stable Diffusion」を低スペックPCでも無料かつ待ち時間なしで使う方法まとめ – GIGAZINE

なお、ここで2度ある「Access repository」への同意が抜けると、Hugging Faceへのアクセス権限が得られず、HTTPリクエストに403が返ってきてしまって、Hugging Faceにホストされている学習モデルファイルがダウンロードできません。

ちゃんと設定できれば、3.79GBある「model.ckpt」ファイルのダウンロードが行われます。

あとは同じように各コードの再生ボタンを押すだけ。なにやらエラー的なメッセージは出ていますがインストールが進行しています。
最後にジェネレーターのUIが表示されたらインストールは完了。「Running on public URL」の後ろに示されているURLにアクセスすると……
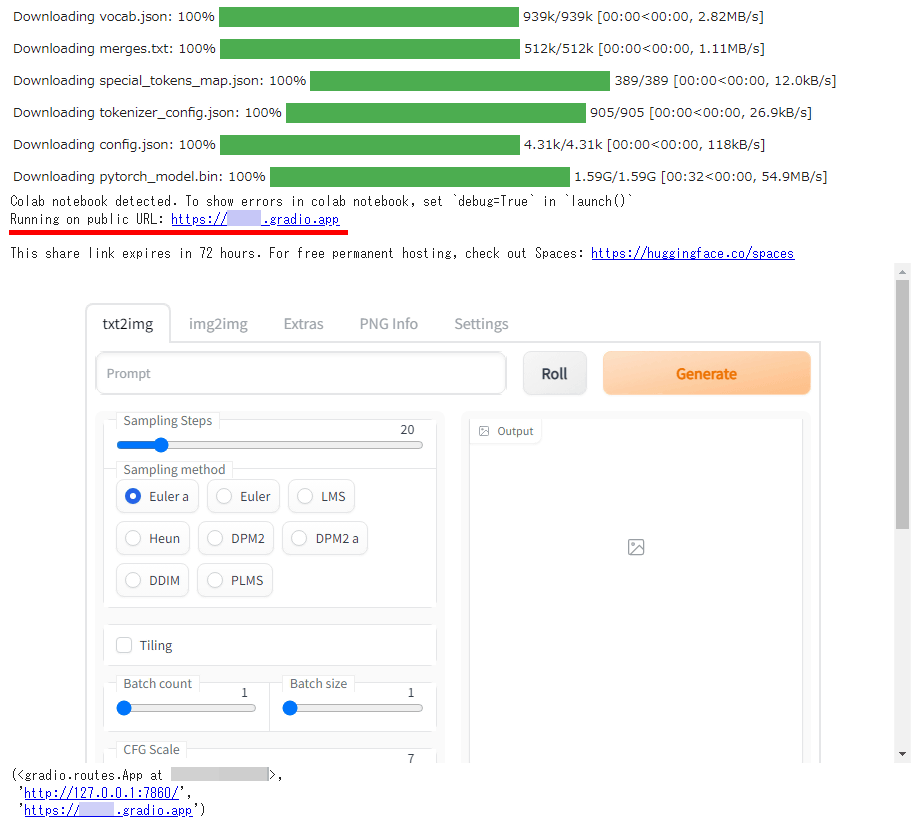
AUTOMATIC1111版Stable Diffusion web UIが起動しました。
画像の生成時間はSampling Stepsが20のとき10秒強、Sampling Stepsが120のとき30秒強で、ローカルで動かすのと大差ないという結果になりました。
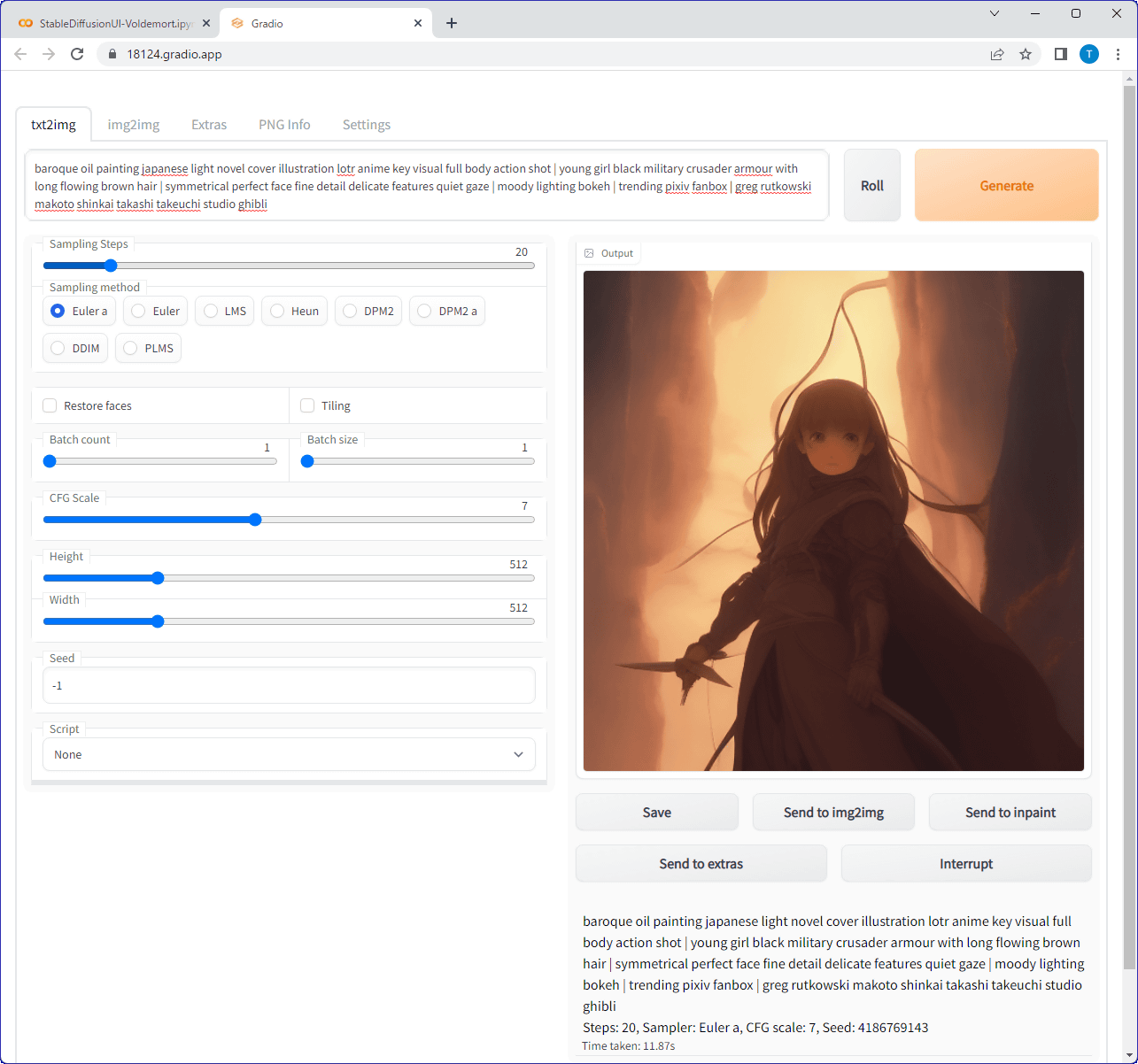
このGoogle Colabを利用する方法なら、NVIDIA製GPUを搭載していないPCでも「Stable Diffusion」を使えます。ただし、Google Colabのランタイムの接続が解除されると使えなくなるため、短期間に何度か使うだけなら便利ですが、長期にわたって使い続けることはできません。
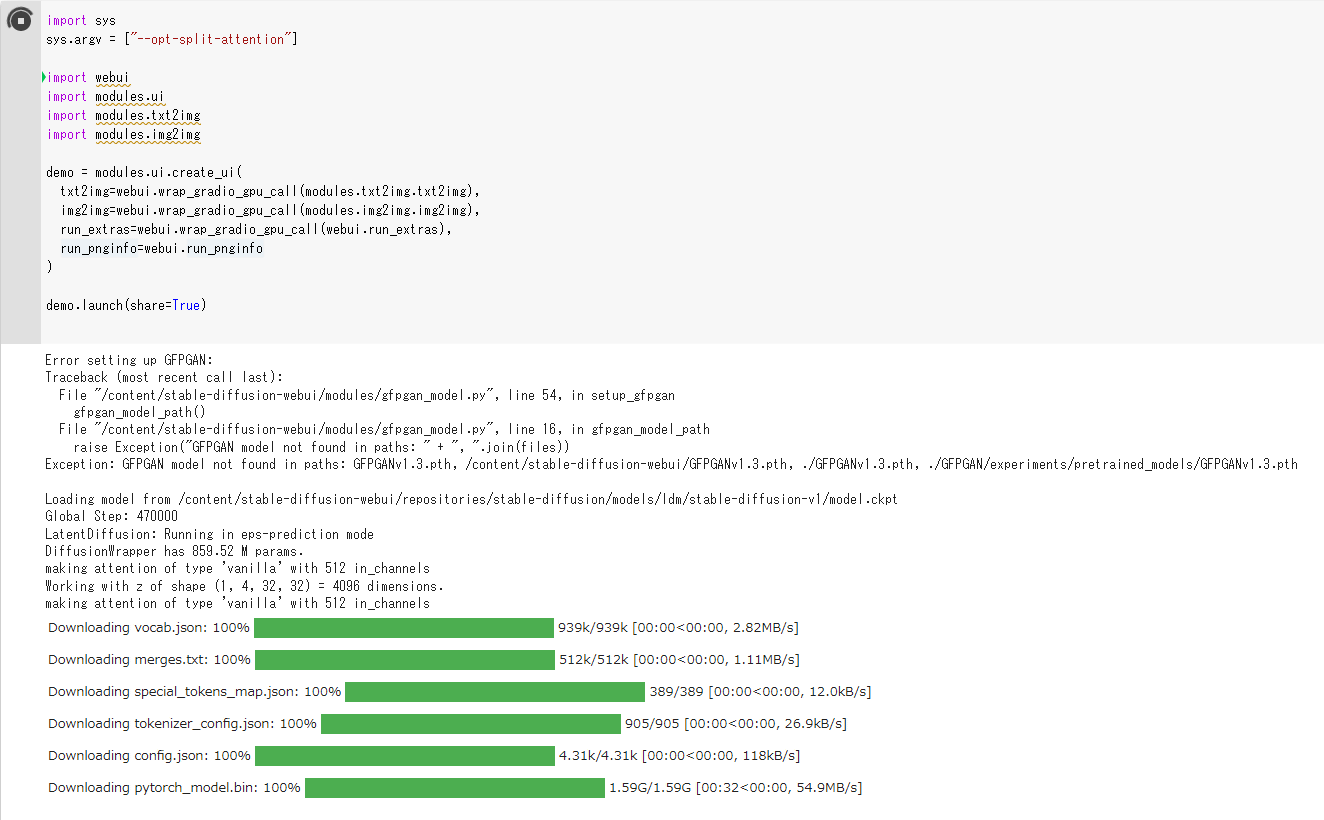
ちなみに、何度か作成を試行する中では、最後の「import sys」から始まるコードで再生ボタンが赤くなり止まってしまうことがありました。ここは「import os」のところとは違い、本来、エラーが出てはいけません。

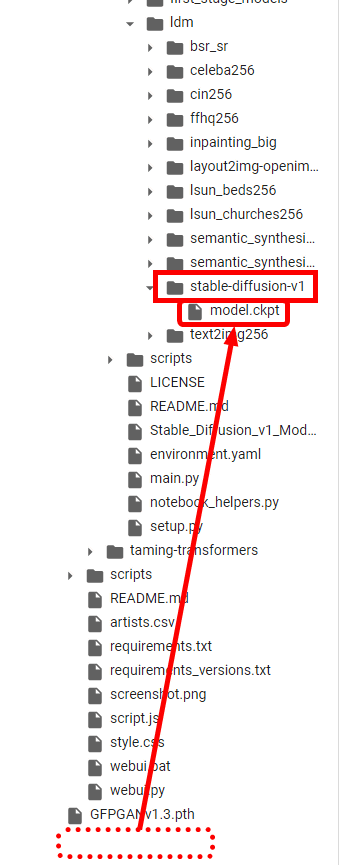
この例だとざっくりと「GFPGAN」関連と「model.ckpt」関連の2つ。

「model.ckpt」については、本来の場所である「/content/stable-diffusion-webui/repositories/stable-diffusion/models/ldm/stable-diffusion-v1/」に見当たらないということなので、画面左側のメニューにあるフォルダアイコンをクリックして構成を確認したところ、「ldm」フォルダ内に「stable-diffusion-v1」フォルダがなく、そもそも「model.ckpt」ファイルが「content」直下に置かれていることがわかりました。

そこで、手動で当該フォルダを作成して「model.ckpt」ファイルを移動するとインストールは進みました。別の試行時にはこのエラーは発生せず、タイミングによって発生したものなのか何なのかはわかりませんでした。
◆3:Windowsで動かす(NVIDIA製GPUが必要)
◆3-1:Pythonのインストール
Python公式サイトから最新版(記事作成時点で3.10.7)をダウンロードします。下記の場所にあるダウンロードボタンをクリック。
Download Python | Python.org
https://www.python.org/downloads/

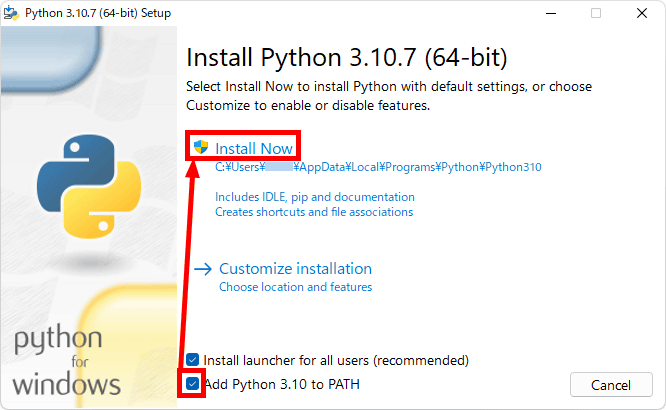
ダウンロードした「python-3.10.7-amd64.exe」を実行。

下部の「Add Python 3.10 to PATH」にチェックを入れ「Install Now」をクリック。
「Close」をクリック。
◆Gitのインストール
Git公式サイトのダウンロードページに行き、「Click here to download」をクリック。
Git – Downloading Package
https://git-scm.com/download/win

ダウンロードしてきた「Git-2.37.3-64-bit.exe」を実行。

インストールオプションは変更せずに進めます。「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Next」をクリック。

「Install」をクリック。

インストール後、「View Release Notes」のチェックを外して「Finish」をクリック。

◆3-3:CUDAのインストール
NVIDIAの開発者向けサイトで「CUDA Tool 11.3」をダウンロードします。以下のリンク先はWindows・64bit向けのインストーラーダウンロードページとなっています。インストール時にファイルをダウンロードするタイプではなく、全ファイルが入っているタイプを選択しているため、ファイルサイズは2.7GBです。
CUDA Toolkit 11.3 Downloads | NVIDIA Developer
https://developer.nvidia.com/cuda-11.3.0-download-archive?target_os=Windows&⌖_arch=x86_64&⌖_version=10&⌖_type=exe_local
右下の「Download (2.7GB)」をクリック。
ダウンロードした「cuda-11.3.0-465.89_win10.exe」を実行。

「同意して続行する」をクリック。
「次へ」をクリック。
チェックボックスにチェックを入れて「Next」をクリック。
「次へ」をクリック。
「閉じる」をクリック。
◆3-4「Stable Diffusion web UI」のインストールと実行
GitHubから「AUTOMATIC1111版Stable Diffusion web UI」をダウンロードします。
GitHub – AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
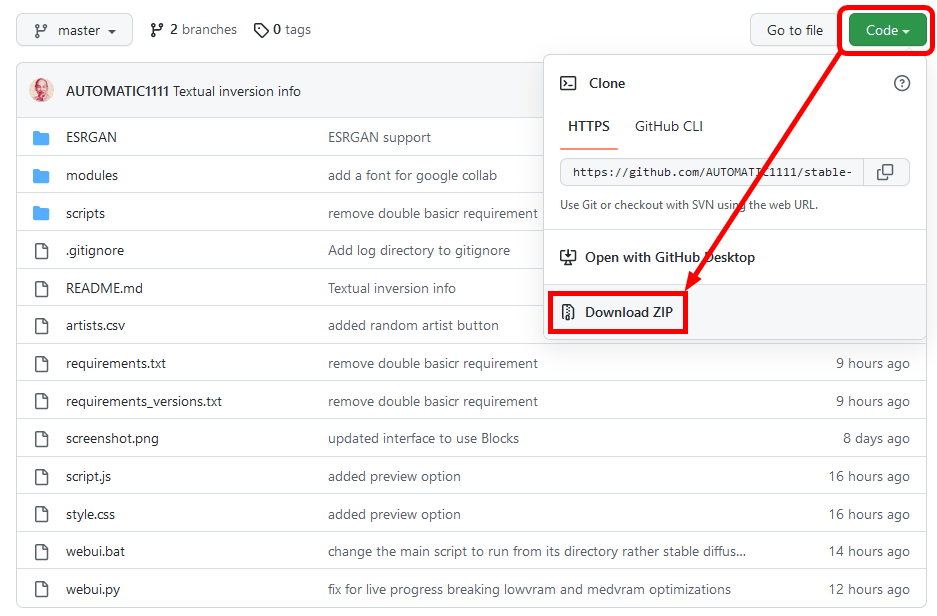
「Code」をクリックし、出てきた「Download ZIP」をクリック。
ダウンロードしたZIPファイルは任意の場所に展開します。
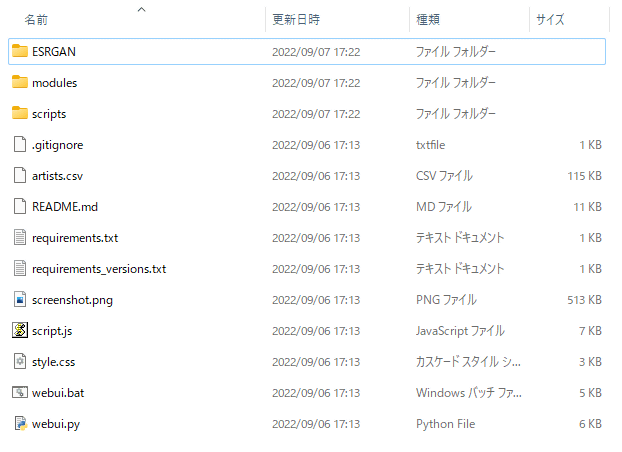
続いて、Hugging Faceから学習モデルファイルをダウンロードします。手順は以下の記事を参照してください。
画像生成AI「Stable Diffusion」の実行環境を無料でWindows上に構築できる「Stable Diffusion web UI」の導入方法まとめ – GIGAZINE

ダウンロードした「sd-v1-4.ckpt」を「model.ckpt」にリネームして、先ほど展開したStable Diffusion web UIのフォルダに入れます。同様に、「GFPGAN」をGitHubからダウンロードして、同じようにStable Diffusion web UIフォルダに入れます。記事作成時点の最新版はv1.3.4です。
できたら、Stable Diffusion web UIフォルダの「webui.bat」ファイルを実行します。
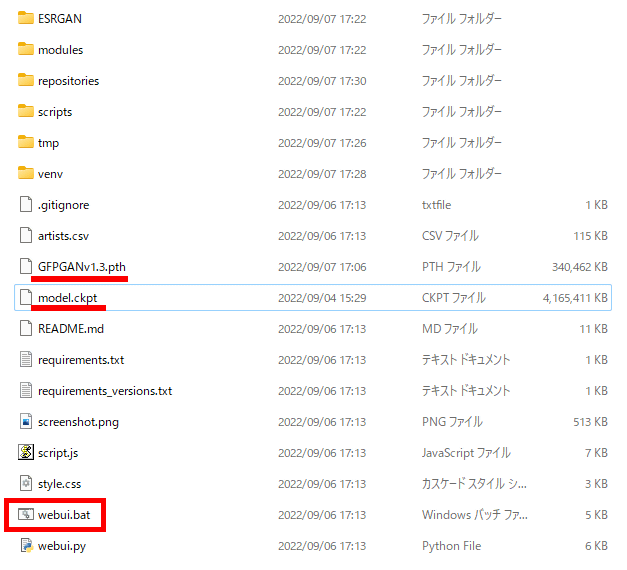
コマンドプロンプトが開き、なにやら文字列が出てきます。「Running on local URL: http://127.0.0.1:7860」と出るので、このURLをブラウザで開くと……

Stable Diffusion web UIが起動しました。
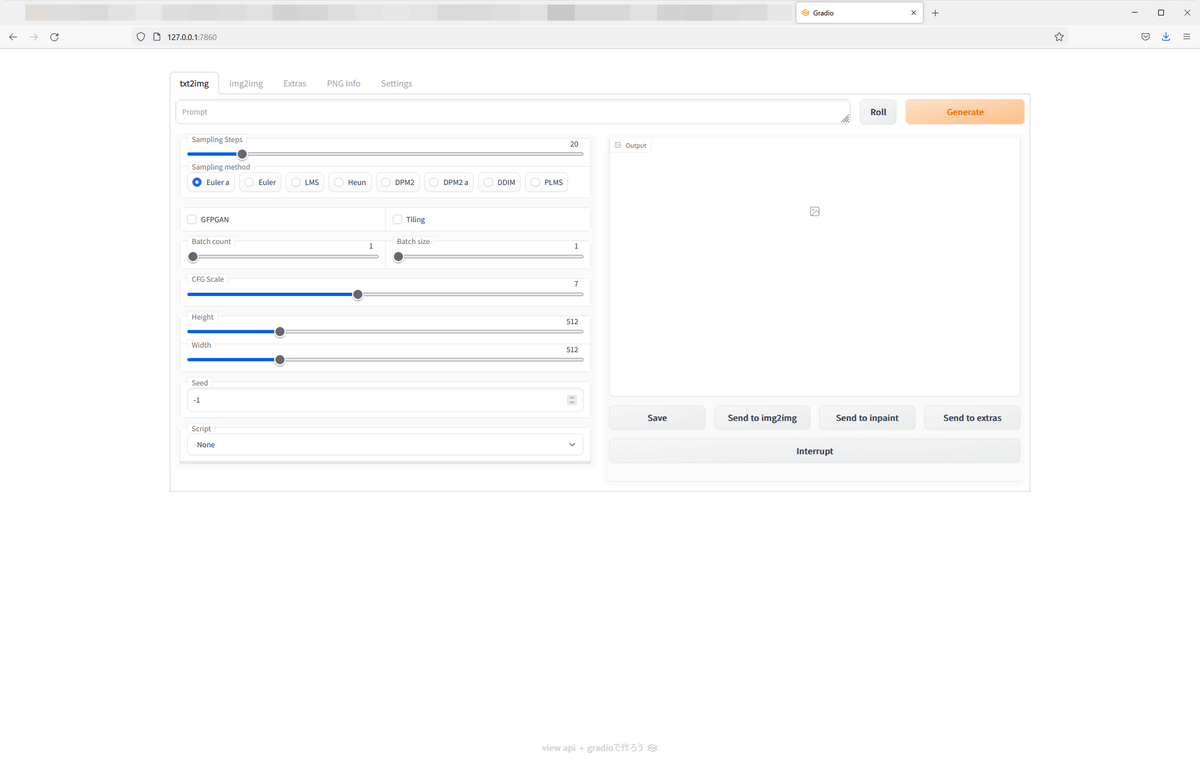
細かい機能の使い方については後日、別途記事にする予定です。
<つづく>
この記事のタイトルとURLをコピーする

