




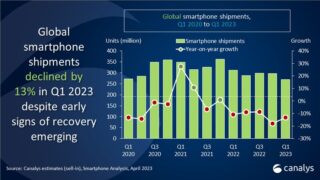













NVIDIA H100 GPU
NVIDIAは、同社のフラグシップカンファレンス「GTC 2022」を、3月21日(現地時間)からオンラインで開催している。2年前のGTC 2020においてAmpereアーキテクチャベースのNVIDIA A100 GPUを発表したが、今回のGTC 2022ではその後継として開発コードネーム「Hopper」(ホッパー)という新しいGPUアーキテクチャを採用した「NVIDIA H100 GPU」(以下H100)を発表した。
H100は、TSMCの4Nカスタムプロセスノード(いわゆる4nm)で製造され、800億トランジスタというモンスターチップになっており、FP8で4P(1ペタ=1,000テラ)FLOPS、FP16で2PFLOPS、TF32で1PFLOPSの性能を実現しており、1チップで1PFLOPSを超える性能を実現していることが大きな特徴となる。
NVIDIAはH100を搭載したサーバーアプライアンスとして、「DGX H100」を同時に発表しており、8つのNVIDIA H100を搭載し、FP8で32PFLOPS、FP64で500TFLOPSの性能を実現する。さらにそのDGX H100を32台組み合わせた」DGX SuperPOD with DGX H100」ではFP8で1E(エクサ)FLOPSという単位が1つあがる性能を実現し、GPUによる並列処理性能をいくらでも必要としているAI学習の世界に新しい基準をもたらすことになりそうだ。
COBOLを開発したグレース・ホッパーからとったHopperのコードネームを持つNVIDIA H100

NVIDIA H100 GPUのモジュール(SXM)
H100は、データセンター向け、その中でも特にHPC(High Performance Computing)に向けたGPU製品となる。NVIDIAはGPUの世代ごとにアーキテクチャの開発コードネームをつけており、従来製品のNVIDIA A100 GPUはAmpere、2世代前のNVIDIA V100 GPUはVoltaという開発コードネームがつけられていたが、今回のH100ではHopperの開発コードネームがつけられている(ご想像の通り、数字の前の頭文字のアルファベットが世代を示している)。
NVIDIAの開発コードネームは科学者の名前から取られており、今回のHopperはプログラミング言語であるCOBOLを開発したとされているグレース・ホッパー氏(Grace Hopper、故人)から取られている。今回NVIDIAはグレース・ホッパーのファーストネーム(名)を来年リリースする予定のArm CPUのコードネームに利用し、ラストネーム(姓)を今回発表するGPUの方に取っている。
なお、前世代になるAmpereの時はコンシューマ/ゲーマー向けにGPUにも同じアーキテクチャ名を利用したが、2世代前のVoltaの時にはコンシューマ/ゲーマー向けのGPUにはTuringという別のアーキテクチャ名を利用していた。今回はそのどちらのパターンになるのか、NVIDIAはまだ何も言っていない。
H100のハイレベルな特徴を箇条書きすると以下のようになっている。
- TSMCの4Nノード(4nm)を利用して製造される、800億トランジスタのチップ
- 新しいHBM3メモリに対応
- 新しいTransformer Engineが搭載されている
- コンフィデンシャルコンピューティングへの対応
- 新しいDPX命令に対応
- 第2世代MIG(Multi-Instance GPU)に対応
- 第4世代のNVLinkを搭載している、PCI Express Gen 5に対応
A100はTSMC 7N(7nm)ノードで、2世代前のV100はTSMC 12N(12nm)で製造されてきた。今回の4N(4nm)は定評のあるTSMC 5N(5nm)の改良版となるプロセスルール世代となるので、7nm世代からの微細化効果は大きいと考えられる。
H100のトランジスタは800億トランジスタとなっており、TSMC N5で製造される2つのM1 MAXをパッケージ上で統合したM1 Ultraが1,140億トランジスタであることを考えれば、1チップで800億トランジスタはさらに巨大チップだと言える。
また、メモリはHBM2からHBM3へと強化されている。それにより、A100世代では2TB/sだったメモリ帯域幅は3TB/sへと引き上げられている。なお、現時点での最大のメモリ容量はA100の後期モデルと同じ80GBになっている。A100がそうだったように後期モデルで強化される可能性は当然あるが、今の所は従来モデルと同じ80GBになっていると考えて良いだろう。
新Transformer Engineに対応することで性能が3~6倍に向上
| NVIDIA H100 | NVIDIA A100 | NVIDIA V100 | |
|---|---|---|---|
| アーキテクチャー | Hopper | Ampere | Volta |
| プロセスノード | TSMC 4N(4nm) | TSMC 7N(7nm) | TSMC 12N(12nm) |
| FP8(利用可能ならTC/TE利用) | 4PFLOPS | ー | ー |
| FP16(利用可能ならTC/TE利用) | 2PFLOPS | 624TFLOPS | 125TFLOPS |
| TF32(利用可能ならTC/TE利用、スパース性利用) | 1PFLOPS | 312TFLOPS | 15.7TFLOPS |
| FP64(利用可能ならTC/TE利用) | 60TFLOPS | 19.5TFLOPS | 7.8TFLOPS |
| メモリ | HBM3 | HBM2 | HBM2 |
| メモリ帯域幅 | 3TB/s | 2TB/s | 900GB/s |
| 最大メモリ容量 | 80GB | 80GB | 32GB |
| PCIe世代(帯域) | PCIe Gen 5(128GB/s) | PCIe Gen 4(64GB/s) | PCIe Gen 3(32GB/s) |
| NVLink | 第4世代 | 第3世代 | 第2世代 |
| NVLink帯域 | 900GB/s | 600GB/s | 300GB/s |
| TDP(SXM) | 700W | 400W | 300W |
今回NVIDIAはHopperアーキテクチャの詳細(例えばCUDAコアはいくつあるのかなど)はまだ語っていない(NVIDIAによればGTCの期間中に公開される予定とのこと)が、1つだけ明らかにしたのは従来NVIDIAがTensorコア(TC)と呼んできたディープラーニング用のアクセラレータを、Transformer Engine(TE)としてアップグレードした点だ。TEのハードウェアとしてはTensorコアの改良版が実装されており、それにソフトウェアを組み合わせることで実現されている。
TEは、Transformer modelsと呼ばれる、ディープラーニングで活用されている演算モデルを利用して浮動小数点演算の高速化を実現。具体的には単精度(FP32)、半精度(FP16)の浮動小数点を利用してAIの演算を行なう時に、演算の正確性に影響を与えることなくFP8に精度を落として演算することで性能を向上させる。またFP8とFP16を混合して演算することが可能になっており、TEが正確性を維持しながら、精度を自動で上げたり下げたりしながら演算する。
これにより、TF32(TensorFloat32、AIの学習で一般的に使われるようになっている行列を利用した32bitの浮動小数点演算)での演算性能、FP8、FP16、FP64などの性能が大きく向上している。
例えば、FP8性能はA100に比べて6倍となる4PFLOPSに、FP16では624TFLOPSだったのが3倍以上の2PFLOPSに、TF32では312TFLOPSだったのがやはり3倍以上となる1PFLOPSに、FP64では19.5TFLOPSだったのが約3倍の60TFLOPSへと、性能が引き上げられる(いずれもTCないしはTEを利用した場合)。
いずれも大きなパフォーマンスアップで、現在AI学習に演算性能が足りていないようなAI研究者や企業などにとっては、置きかえるだけで3~6倍の性能向上を実現するというのは朗報と言えるだろう。
コンフィデンシャルコンピューティングへの対応やマルチインスタンスGPUの機能が強化
GPUとしての命令セット周りの強化としては、コンフィデンシャルコンピューティングへの対応、新しいDPX命令への対応、そして第2世代MIG(Multi-Instance GPU)の対応という3つが挙げられる。
コンフィデンシャルコンピューティングとは、サーバーCPUで一般的に利用されているアプリケーションが利用するメモリ空間を分離して保護することで、データの漏洩を心配せずに演算するための仕組みだ。既にCPUにはそうした機能が備わりつつあるのだが、GPUには実装されてこなかった。H100ではそうした機能が標準で搭載されており、例えばプライバシーの保護が重要になる医療データなどを保護したままGPUで演算することが可能になる。
新しいDPX命令は新しいアルゴリズムを利用することで、ゲノムや量子コンピュータ、ルート最適化などの、従来型の演算では難しかった最適化を実現するプログラミングモデルになる。それらの演算をDPX命令を利用して行なうことで、最大40倍の性能向上が実現できるとNVIDIAは説明している。
そして第2世代MIGは、既にNVIDIAがA100世代で導入していたGPUの機能分割機能をさらに機能向上させたものとなる。A100で導入したMIGは、GPUの機能を最大で7つまで分割して、分割したそれぞれの部分を物理的なGPUと同じように使えるようにする機能だ。例えば、GPUをサーバーに導入していると、物理マシン上に7つの仮想マシンがあったとしよう。通常であれば、1つの物理GPUを仮想化して、7つのマシンを共有することになるため、どうしても性能上課題が発生することになるし、パブリッククラウドの事業者が仮想GPUとしてユーザーに提供する場合には、データの保護の観点でも課題があると言える。そこで、MIGでは物理的に最大7つのGPUがあるのと同じ状態になるので、そうした問題を解決できるのだ。
今回のH100ではそれが第2世代となり、インスタンス(パブリッククラウドでの顧客の実行環境のこと)ごとにメモリ空間を完全に分離し、I/Oも完全に分離することができるようになり、さらにインスタンスそれぞれがコンフィデンシャルコンピューティングを利用することができるため、より高いセキュリティーをもってMIGを利用することが可能になる。
Switch利用で最大256基を1GPUとして扱うことができる

NVLink Switch
I/O関連の強化もH100の大きな特徴となっている。A100は、大きく分けて2つのI/Oを持っていた。1つはNVLinkで、これはGPUとGPUを直接接続して、複数のGPUを1つのGPUとして利用するいわゆるスケールアップに利用されてきた。そしてもう1つはPCI Expressで、こちらはCPUと接続や、InfiniBandやEthernetなどのサーバーブレード内の接続(いわゆるスケールアウト)に利用されてきた。
今回のH100ではそのいずれもが大きく強化されている。NVLinkは第4世代に強化されており、第3世代のNVLinkを採用していたA100の600GB/sから帯域幅が引き上げられ、900GB/sとなっている。また、PCI ExpressもA100ではPCI Express Gen 4(64GB/s)だったのが、PCI Express Gen 5(128GB/s)へと強化されている。
ただし、こうしたI/O周りや性能が大きく向上していることで、消費電力は上がっている。NVIDIAが公開したデータによれば、H100のモジュール(SMX)フォームファクタでのTDPは700Wになっており、A100の400W、V100の300Wから大きく引き上げられている。つまり、H100を多数搭載したサーバーシステムは消費電力が上がることになり、従来のA100ベースのシステムから置きかえる場合は、ラックの電源周りの強化は必須だろう。

DGX H100、H100を8つ搭載している
H100を搭載したNVIDIAブランドのサーバーアプライアンスはDGX H100という名称で、8つのH100を搭載しており、FP8で32PFLOPS、FP64で0.5PFLOPSの性能を実現しており、それぞれ「DGX A100」と比較して6倍および3倍の性能向上になるという。

DGX H100の内部構造
そのDGXを32台つなげたシステムとしてNVIDIA DGX SuperPOD with DGX H100も用意されており、最大で256基のGPUをNVLinkで接続できる新しいNVLink Switchを利用することで、FP8で1E(エクサ)FLOPSの性能を実現可能になる。
また、NVIDIA DGX SuperPOD with DGX H100を18台接続したシステムとして「NVIDIA EoS」と呼ばれるスーパーコンピューターも構築可能で、その場合にはFP8で18EFLOPSの性能を実現できる。

NVIDIA DGX SuperPOD with DGX H100
H100を搭載した製品は第3四半期(7月~9月期)から出荷開始予定になっており、DGXシリーズはNVIDIAのリセーラーなどから販売が行なわれる予定だ。アクセラレータカードや搭載サーバーは、Atos、BOXX Technologies、Cisco、Dell Technologies、富士通、GIGABYTE、H3C、Hewlett Packard Enterprise、Inspur、Lenovo、Nettrix、SupermicroなどのOEM、ODMベンダーからも提供される予定で、こちらも第3四半期から提供開始される計画だ。


コメント