
















GPT-4のような高性能なモデルでも、APIの呼び出しコードを生成させるとかなりの確率で間違ったコードを生成してしまいます。「Gorilla」はAPIを呼び出すコードの生成に特化するようにファインチューニングが行われており、精度の高い呼び出しコードを生成できるだけでなく、情報検索器(Information Retriever)と一緒に利用するとAPIの更新にリアルタイムで追従できるという驚異的な機能が付いたモデルです。
Gorilla
https://shishirpatil.github.io/gorilla/
Gorillaのトレーニングにおいては、「Torch Hub」「TensorFlow Hub」「HuggingFace」という3つのソースから収集した1645個のAPI呼び出しコードをもとにAIが1万6450個の命令とAPIのセットを作成し、その1万6450個の命令セットでファインチューニングを行ったとのこと。推論時には情報検索器を使ってAPIのデータベースから関連APIを補完することで幻覚(ハルシネーション)を防いで精度を向上できると述べられています。

APIの呼び出しコードを生成するテストを「GPT-4」「Claude」「Gorilla」の3つで試したところ、GPT-4は幻覚を見てしまい、Claudeは間違ったライブラリを選択。一方でGorillaは適切なライブラリで適切な呼び出しコードを記述することができたとのこと。

記事作成時点で、Gorillaはファインチューニングの元になったベースごとに「LLaMA版」「MPT版」「Falcon版」の3つが存在しています。このうちMPT版とFalcon版はApache 2.0ライセンスで公開されており、モデル・トレーニングデータがダウンロード可能なほか、商用利用も可能となっています。
◆デモを使ってみた
すぐに実行できるデモも用意されていたので早速使ってみます。「Try Gorilla in 60s」と書かれたメッセージの隣にある「Open in Colab」をクリック。

テスト用のコードがGoogle Colaboratoryで開くので「ドライブにコピー」をクリックします。

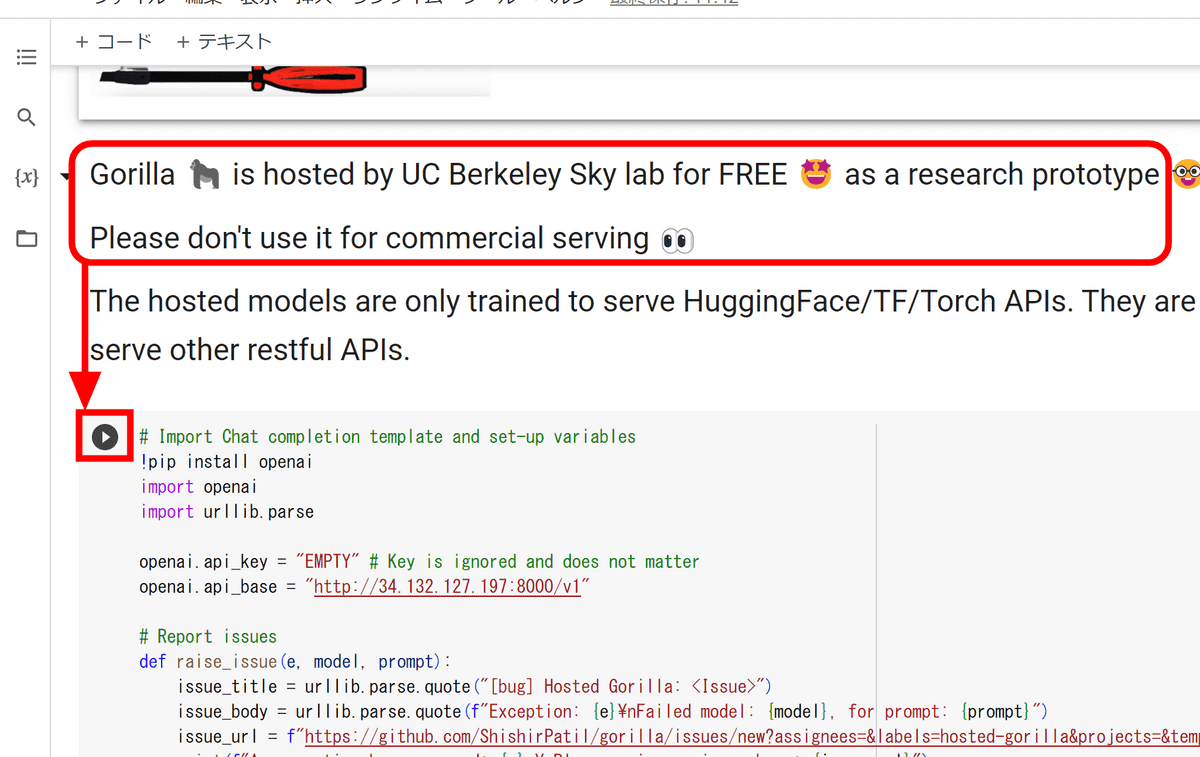
これでファイルを編集できるようになりました。デモ版はカリフォルニア州立大学バークレー校のSky labでホスティングされているとのこと。研究用なので商用利用はNGと大きく注意が書かれています。この注意のすぐ下にある再生マークをクリックして実行します。
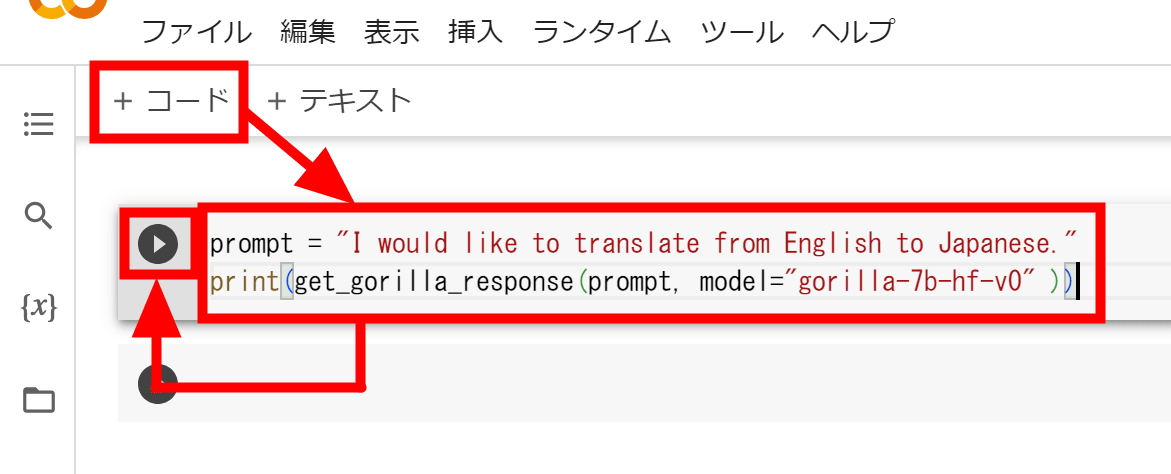
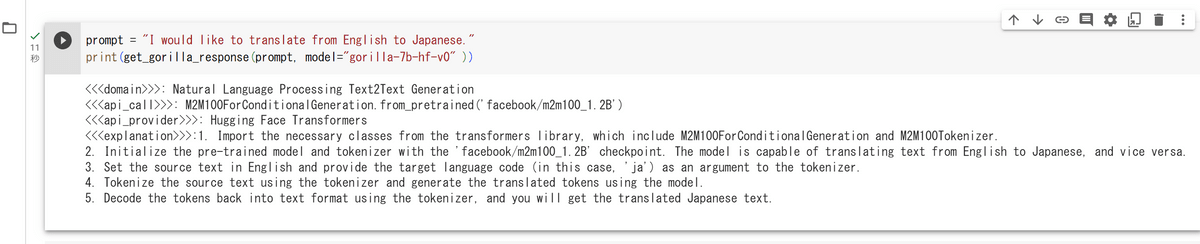
これで準備が整いました。「get_gorilla_response」関数を実行すればGorillaの返事を確認できます。画面上にある「コード」をクリックしてコードブロックを追加し、get_gorilla_response関数の結果を表示するようにして左の再生ボタンをクリックして実行します。プロンプトは「英語を日本語にしたい」という内容を英語で記述しました。
10秒ほどで返事が返ってきました。「facebook/m2m100_1.2B」というモデルが指定され、さらにその使用方法が解説されています。先ほどのGPT-4やClaudeとの比較画像的に、コードが直接生成されるのかと思っていましたが、返事は解説のみだったので、この解説を元に人間が書く……ということのようです。なお、M2M100のドキュメントを見て検証してみましたが、おそらく正しそうな記述となっていました。
この記事のタイトルとURLをコピーする

