


















画像に含まれる文字をテキストデータ化する光学文字認識(OCR)は、請求書やレシート、名刺などの印刷物をデジタル化する手法として広く使われています。そんなOCRをディープラーニングフレームワークで実現したのが、オープンソースのOCRシステム「PP-OCRv2」のデモ版となる「PaddleOCR」です。
PaddleOCR – a Hugging Face Space by akhaliq
https://huggingface.co/spaces/akhaliq/PaddleOCR
GitHub – PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)
https://github.com/PaddlePaddle/PaddleOCR#PP-OCRv2
PaddleOCRおよびPP-OCRv2は、Baiduが開発したディープラーニングのフレームワーク「PaddlePaddle」に基づいて作成されています。技術研究者であるYuning Du氏らが開発したPP-OCRv2は、ディープラーニングにより中国語・英語・日本語を始めとする80の言語を認識し、テキストとして出力。効率化や高速化が図られ、全てオープンソースとして開発されているとのこと。

そんなPP-OCRv2のデモ版であるPaddleOCRが公開されていたので、実際に使用してみます。まずはPaddleOCRのトップページにアクセスします。

画面左の「Drop Image Here or Click to Upload」と書かれた部分をクリックすることでエクスプローラーが開くので、OCRを行いたい画像を選び、アップロードします。

アップロードが完了したら、解析したい言語を「language」から選び、「Submit」をクリックします。今回は日本語で解析します。

しばらくすると解析が完了し、画面右に画像ファイルとして結果が表示されました。解析にかかった時間は78.69秒でした。解析結果は画像ファイルとして出力されるため、テキストをコピーすることはできません。
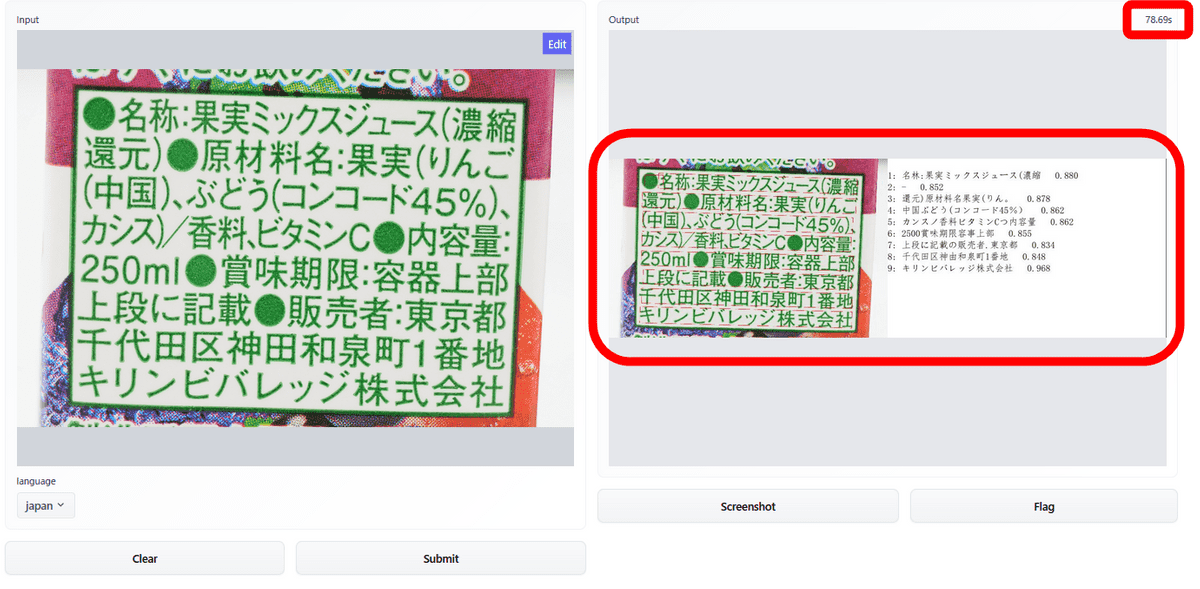
解析結果を詳しく見てみるとこんな感じ。各段落から読み取った文字情報と、その精度が数字で記されています。「果実ミックスジュース」「原材料名」などの単語を読み取ってはいますが、「/」を「ノ」としていたり、「ml」を「0」としていたりと、少し精度に粗さが見られます。

次はPS5用コントローラー「DualSense」のパッケージで試してみます。

日本語の設定で解析したところ、「PlayStation」を「PIqy5LatI0n」、「Wireless Controler」を「WIrelesSContr0ler」と読み取っているなど、やはり少し精度に難がありました。かかった時間は1.91秒でした。

解析言語を英語に変更して再度解析したところ、かなり高い精度で読み取ってくれたので、アルファベットの読み取り時などは言語設定を変更するとよさげ。

PaddleOCRは英語であればかなり高い精度で読み取ってくれるのですが、デモ版であるためか日本語だと精度がイマイチな様子でした。「よく知らない外国語が書かれた商品のパッケージの内容を読み取る」といった使い方ができると思い使い始めてみたものの、テキストで出力されるわけではないのでそのような使い方はできず、あくまでデモ版であることを痛感しました。
なお、GitHubではPaddleOCRのツールキットが配布されています。
この記事のタイトルとURLをコピーする

