

















画像生成AI・Stable Diffusionを導入するにはNVIDIA製GPUを搭載したPCのほかにPythonやAnacondaなどの知識が必要で、ローカル環境に導入するには少し敷居が高いところがありました。しかし、2022年8月に一般公開されて以降、多くの開発者によって誰でも簡単にStable Diffusionをローカル環境に導入可能でかつGUIで操作できるツールが次々と開発されています。「Stable Diffusion web UI(AUTOMATIC1111版)」はその中でも他のUIには搭載されていない機能も盛り込まれた決定版とも言えるツールで、その中でも特に画像生成にお役立ちな機能である「Prompt matrix」と「X/Y plot」を実際に使ってみました。
GitHub – AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
Stable Diffusion web UI(AUTOMATIC1111版)をローカル環境に導入するやり方は以下の記事にまとめられています。

また、Stable Diffusion web UI(AUTOMATIC1111版)の基本的な使い方は以下の記事を読むとよくわかります。

Stable Diffusion web UI(AUTOMATIC1111版)を起動。左下に「Script」というプルダウンがあります。

Scriptのプルダウンから「Prompt matrix」を選択。

Prompt matrixは、画像生成の時に入力する文字列(プロンプト)で通常は「,」でキーワードを区切るところを、「|」で区切ることで総組み合わせして画像を生成できる機能です。例えば、通常は「a busy city street in a modern city, illustration ,cinematic lighting(近代都市のせわしない街道、イラスト、映画のような照明)」というプロンプトで画像を生成しますが、Prompt matrixで「a busy city street in a modern city | illustration | cinematic lighting」というように「|」で区切って入力することで、「a busy city street in a modern city」に「illustration」と「cinematic lighting」を組み合わせた画像を生成できます。
実際に、「a busy city street in a modern city | illustration | cinematic lighting」をプロンプトとして入力して「Generate」をクリックします。
すると、以下のような画像が生成されました。
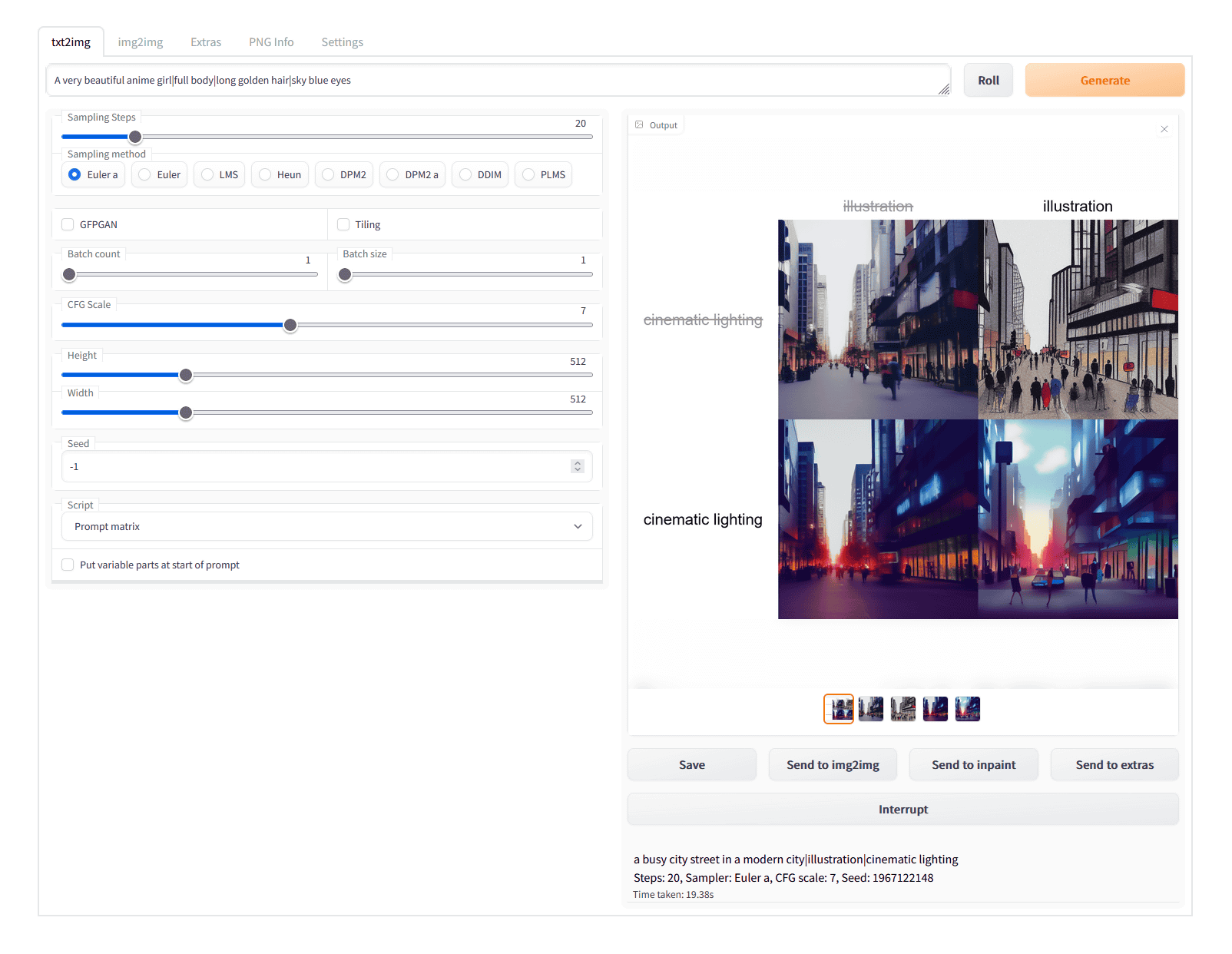
最初のプロンプトである「a busy city street in a modern city」をベースに、「illustration」と「cinematic lighting」の有無による4パターンでそれぞれ画像が出力されています。「illustration」と「cinematic lighting」がどちらも無視された左上が「a busy city street in a modern city」のみで出力した画像で、これに「illustration」のみを組み合わせた画像が右上、「cinematic lighting」のみを組み合わせた画像が左下、そして「illustration」と「cinematic lighting」の両方を組み合わせたものが右下になります。

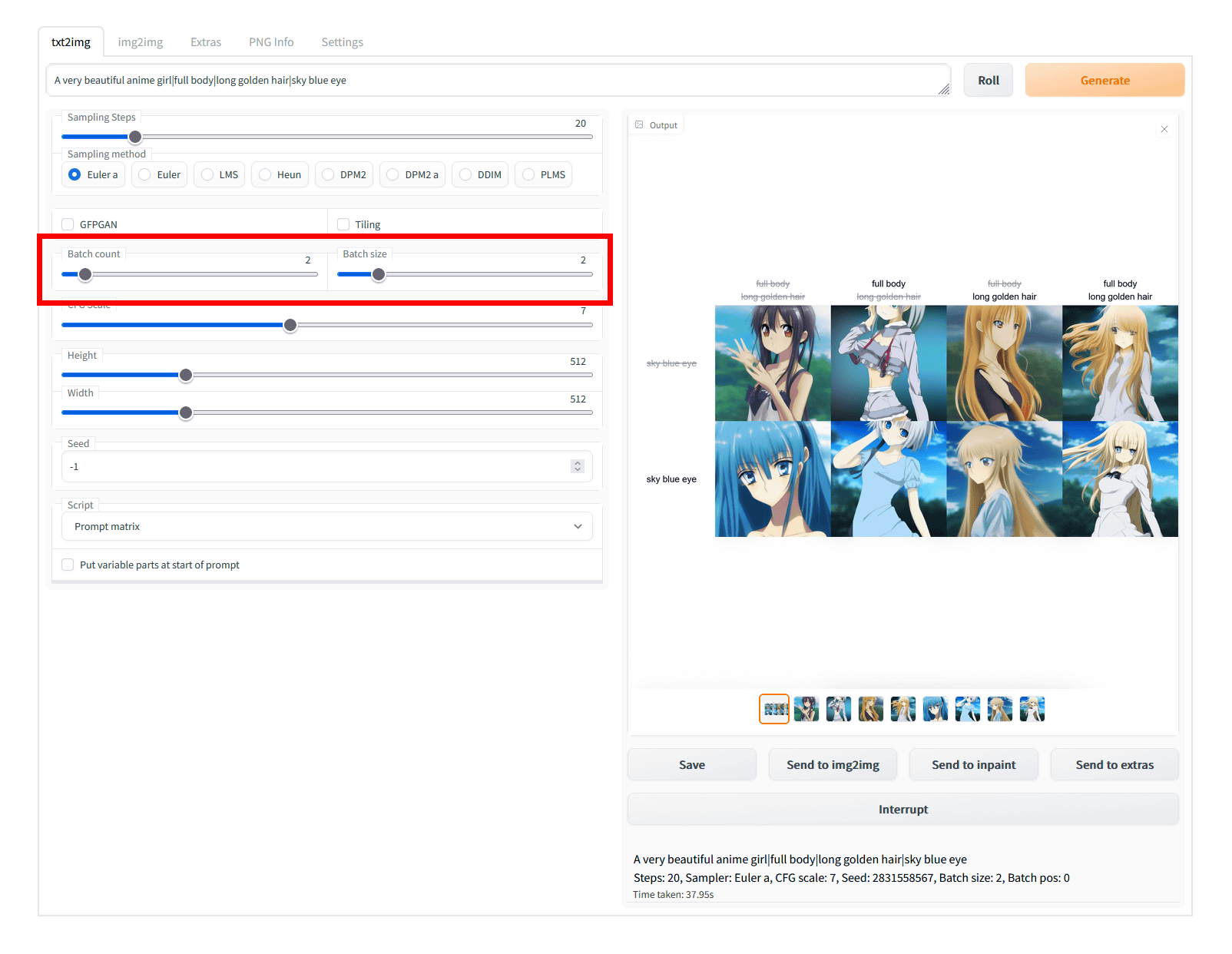
以下の画像は「A very beautiful girl | full body | long golden hair | sky blue eye」という4要素で構成されたプロンプトをPrompt matrixで出力した結果。先頭の「A very beautiful girl」をベースに、列が何もなし・「full body」 のみ・「long golden hair」のみ・「full body」「long golden hair」両方の4列 、行が「sky blue eye」なし、「sky blue eye」ありの2行で、合計8枚の画像が生成されています。

Batch countとBatch sizeを変更しても次の「X/Y plot」と違って1枚ずつしか生成されません。
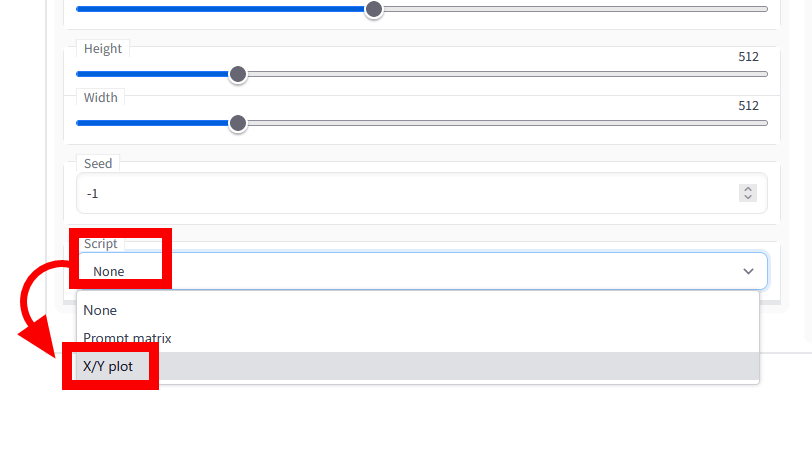
次に、「X/Y plot」を使ってみます。「Script」のプルダウンから「X/Y plot」を選択。
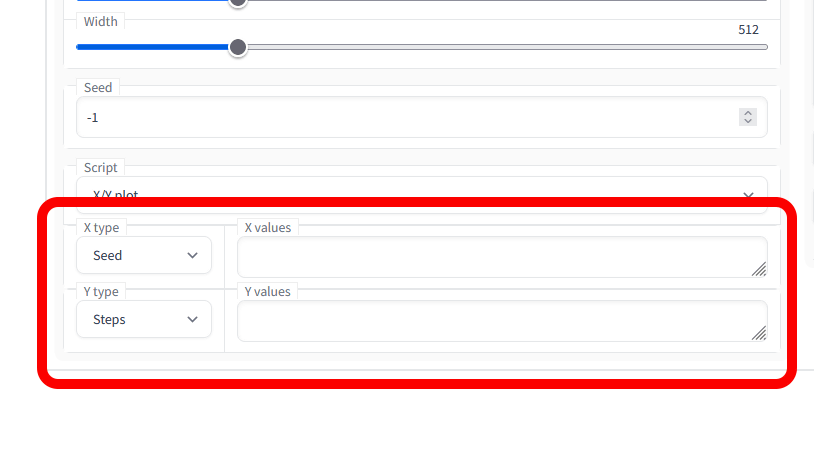
すると、「X Type」「Y Type」という2種類の選択項目が出現しました。
それぞれで選べるのは「Seed(シード)」「Steps(生成ステップ数)」「CFG Scale(CFGスケール、高いほどプロンプトに近いイメージを出す変数)」「Prompt S/R(末尾のプロンプト)」「Sampler(サンプラー)」です。
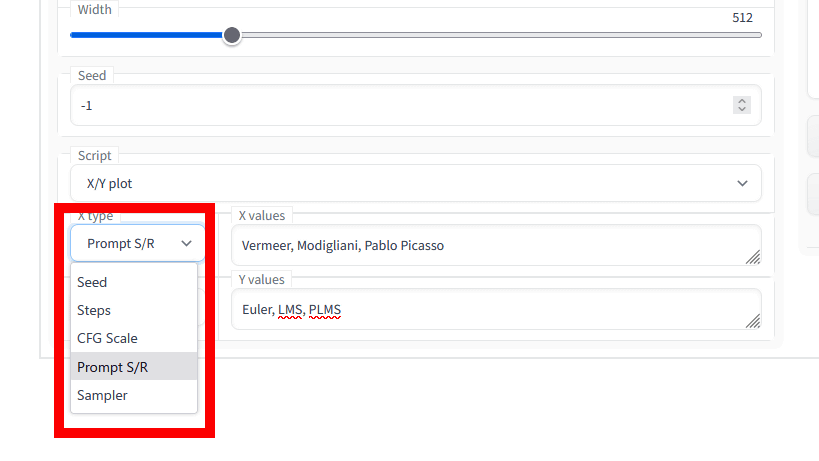
今回はプロンプトに「The Milkmaid, oil painting, art by Vermeer(牛乳を注ぐ女、油絵、フェルメールの作品)」と入力。X Typeには「Prompt S/R」を選択して「Vermeer, Modigliani, Pablo Picasso(フェルメール、モディリアーニ、パブロ・ピカソ)」、Y Typeには「Sampler」を選択して「Euler, LMS, PLMS」と指定し、画像を生成しました。
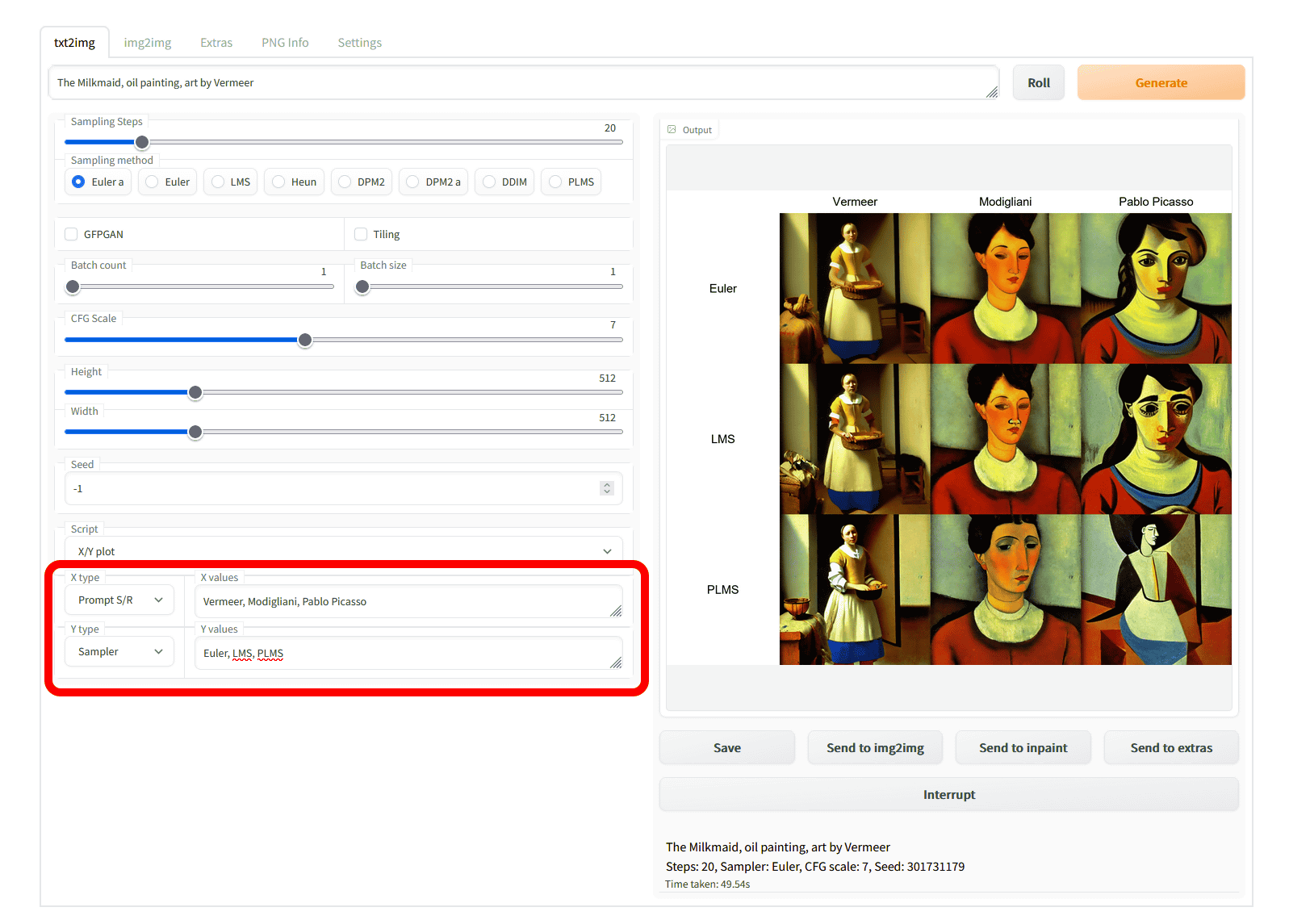
生成された画像を見るとこんな感じ。列が画家の画風で、行がサンプラーの種類になっています。各画家による画風の差もわかりやすく出ていますが、サンプラーによる差もかなりはっきりとわかります。フェルメール風とモディリアーニ風の場合は構図がほとんど同じですが、タッチにかなり差が出ています。また、ピカソ風の場合はPLMSサンプラーだけなぜかより引いた構図になっています。

今度はX Typeに「Steps」を選択して「10,20,30」を、Y Typeに「Seed」を選択して「123,456,789,123456」を指定し、同じプロンプトで出力してみました。シード値が変化することで絵が全くことなるものが出ています。また、生成ステップ数が増えるほど、絵の細かい描き込みの量が増えている印象。

さらに今度はY Typeに「CFG Scales」を選択して「7,8,9,10」を指定し、プロンプトとX Typeはそのままで画像を出力してみました。生成ステップが10の場合、CFGスケールを上げていくにつれて、生成された画像が「牛乳を注ぐ女」にかなり近づいているのがよくわかります。一方で、生成ステップ数が30だと、CFGスケールをあげても出力結果は大きく変わっていません。

また、X/Y plotではBatch countとBatch sizeを変更することで、1セル当たりに複数枚の画像を生成することも可能。以下の画像は「beautiful woman with braided blond hair, red eyes, wearing a camisole, sitting on her bed, highly detailed, in the style of and ilya kuvshinov and greg rutkowski and shinkai makoto, kawaii, high quality anime artstyle, intricate」というプロンプトで生成した画像で、X Typeで「Steps」を選択して「40,80」に、Y Typeで「CHG Scale」を選択して「7,9」に指定し、Batch countとBatch sizeをそれぞれ「4」に設定しています。
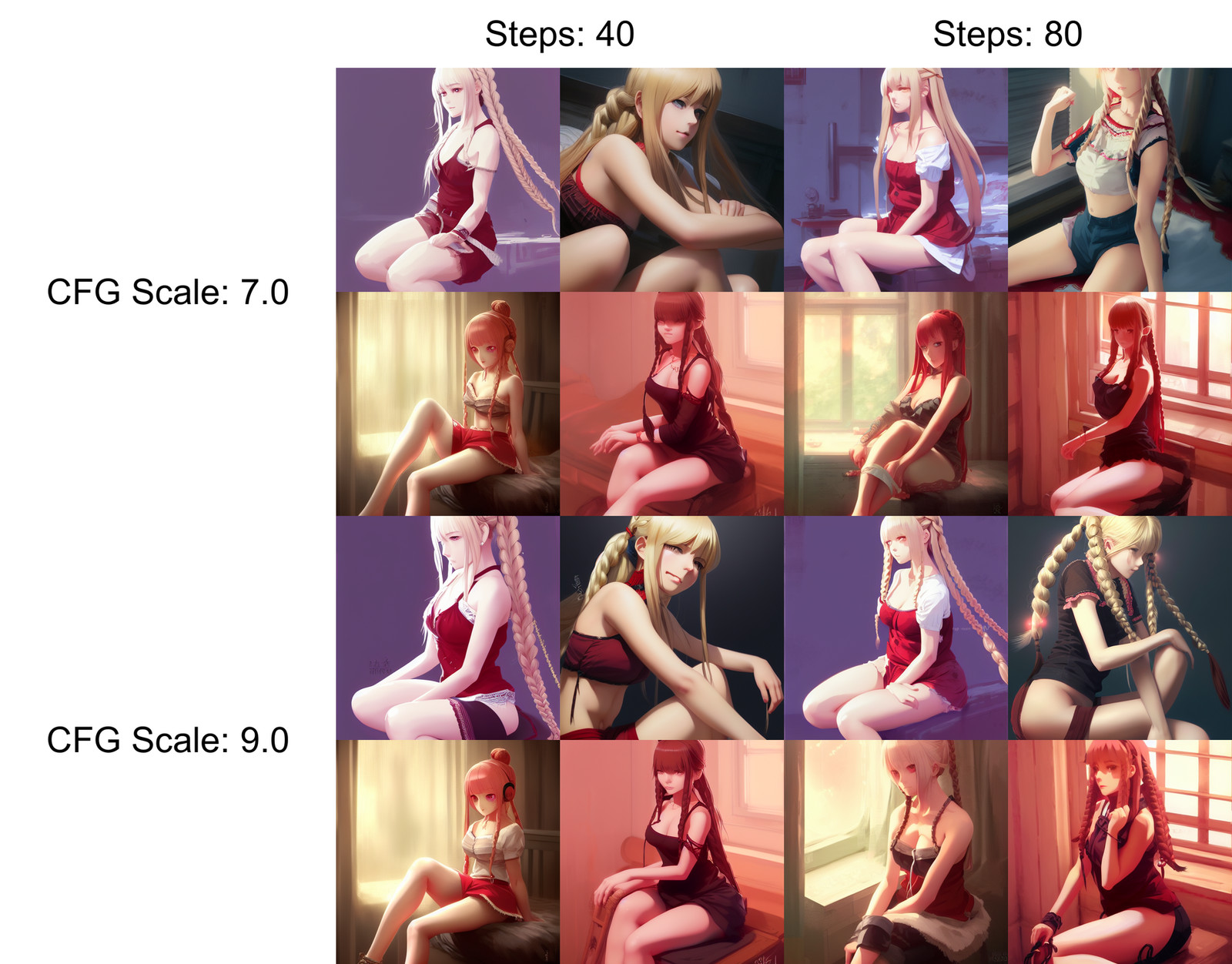
Stable Diffusionでより理想に近い画像を生成するためには、さまざまなキーワードを組み合わせてプロンプトとして入力したり、ステップ数やCFGスケールなどの細かい設定を変更する必要があり、おびただしい数の試行錯誤を繰り返さなければなりません。しかし、「Prompt matrix」と「X/Y plot」を駆使すれば、何度も生成しないとわからない理想のプロンプトと設定をより簡単に把握することが可能なので、どうしても自分の好きな画像が作れなくて困っているという人はぜひ使ってみてください。
なお、次回からは入力された画像から自動的に生成する「img2img」の各機能を順番に解説していく予定です。
この記事のタイトルとURLをコピーする

