

















AI研究団体・OpenAIが発表して話題を呼んだ対話型AI「ChatGPT」は、テキスト自動生成AI・GPT-3の派生形である「GPT-3.5」をファインチューニングした自然言語処理モデルです。チューリッヒ工科大学で機械学習とロボティクスの博士号課程に進んでいるダニエル・デュガス氏が、GPT-3が行っている数学的処理工程について解説しています。
The GPT-3 Architecture, on a Napkin
https://dugas.ch/artificial_curiosity/GPT_architecture.html
◆入力/出力
まずGPTの「入力」とは一連のN個の単語のことで、「(入力)トークン」とも呼ばれます。そして、GPTの「出力」とは、入力トークンの最後に配置される可能性が最も高いと推測される単語です。例えば「not all heroes wear(すべてのヒーローが着ているわけではない)」と入力すると、GPTは「capes(マントを)」と出力します。この時、「pants」や「socks」という単語も推測されていますが、可能性としてはcapesが最も高くなります。

入力を重ねていくと、以下のように出力は変化していきます。このままだと入力を重ねていくにつれて果てしなく長くなっていくため、GPT-3の場合は入力シーケンスの長さを2048単語までに制限しています。
| 入力 | 出力 |
| not all heroes wear | capes |
| not all heroes wear capes | but |
| not all heroes wear capes but | all |
| not all heroes wear capes but all | villans |
| not all heroes wear capes but all villans | do |
◆符号化(Encoding)
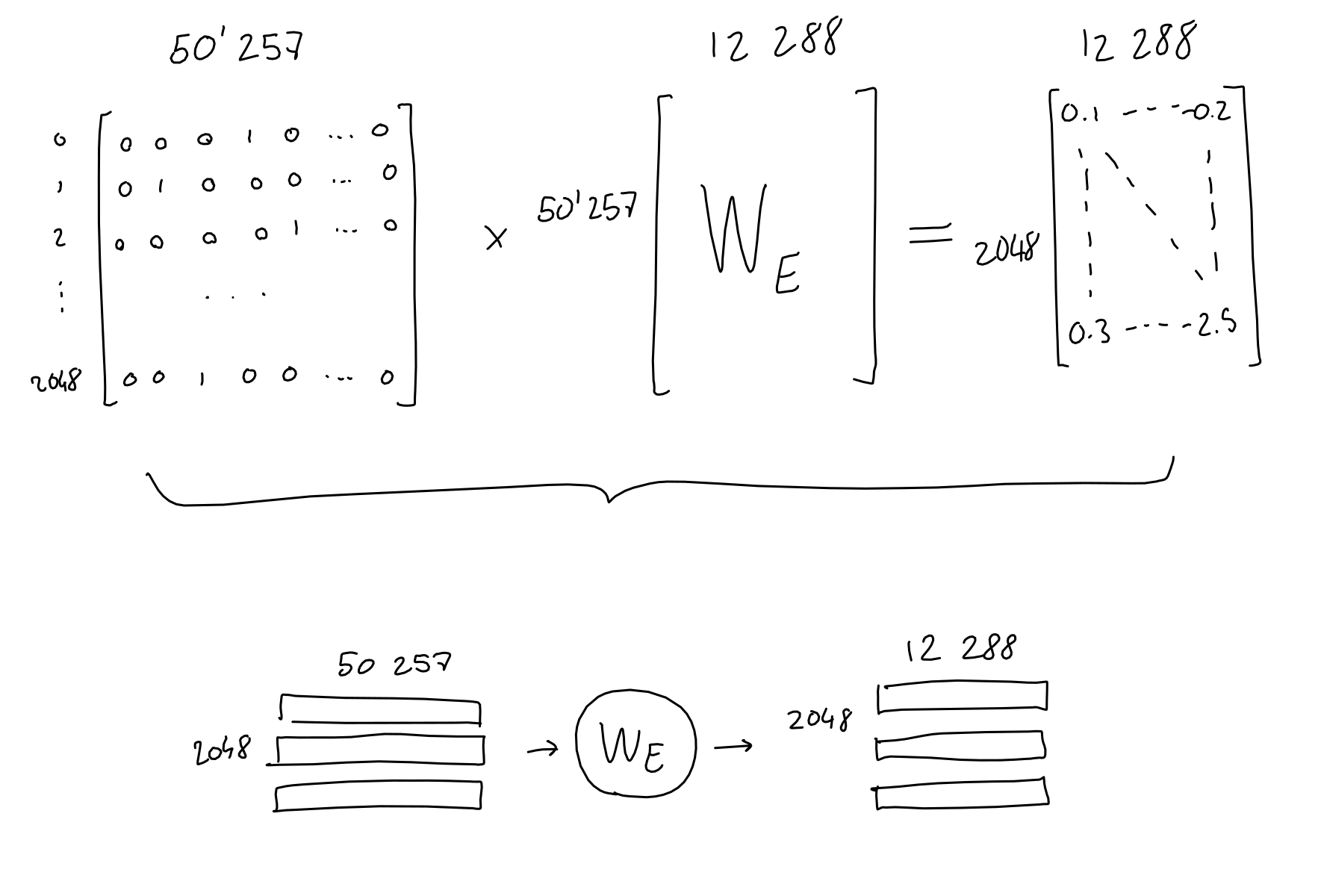
しかし、GPTはあくまでもアルゴリズムであり、人間のように単語を理解しているわけではありません。アルゴリズムが単語を認識するためには、単語を数値のベクトルに変換する必要があります。GPTには5万257個のトークンが登録されており、IDが振られています。

GPT-3は効率化のため、「バイト対符号化」によるトークン化を行っているそうで、実際はGPTに登録されているトークンは完全な単語ではなく、テキスト中に頻繁に現れる文字のグループになっているそうです。例えば「Not all heroes wear capes」の場合、[not][all][heroes][wear][cap][es]というトークンに分割され、それぞれをIDに変換すると[3673][477][10281][5806][1451][274]になります。
トークンはすべて5万257次元の行ベクトルに変換されます。例えば[not]というトークンの場合、IDは3673なので、「3673番目の成分だけが1で残りはすべて0」のベクトルで表現されます。2048個のトークンを入力すると2048個の5万257次元の行ベクトルに変換され、最終的には以下のように「0と1で構成された2048行×5万257列の行列」に合成されるというわけです。これがトークンの符号化です。

◆埋め込み(Embedding)
しかし、変換されたベクトルのほとんどの成分は0で構成されています。そこで、0と1の成分で構成された行列ではなく、より小さな次元空間に線形射影した時の長さを成分とするベクトルに変換します。例えば射影する次元を2次元にした場合、以下の図のように各トークンをXY平面に配置し、その座標データに置き換えることになります。

もちろん実際に射影される次元は2次元ではなく、GPTでは1万2288次元を使用するとのこと。各トークンのベクトルに学習済みの埋め込みネットワークの重みが乗算され、1万2288次元の埋め込みベクトルに変換されます。
つまり、「2048行×5万257列の行列」に、12288次元に変換する「5万257行×1万2288列の行列」を掛け合わせ、2048行×1万2288列の埋め込み行列に変換します。
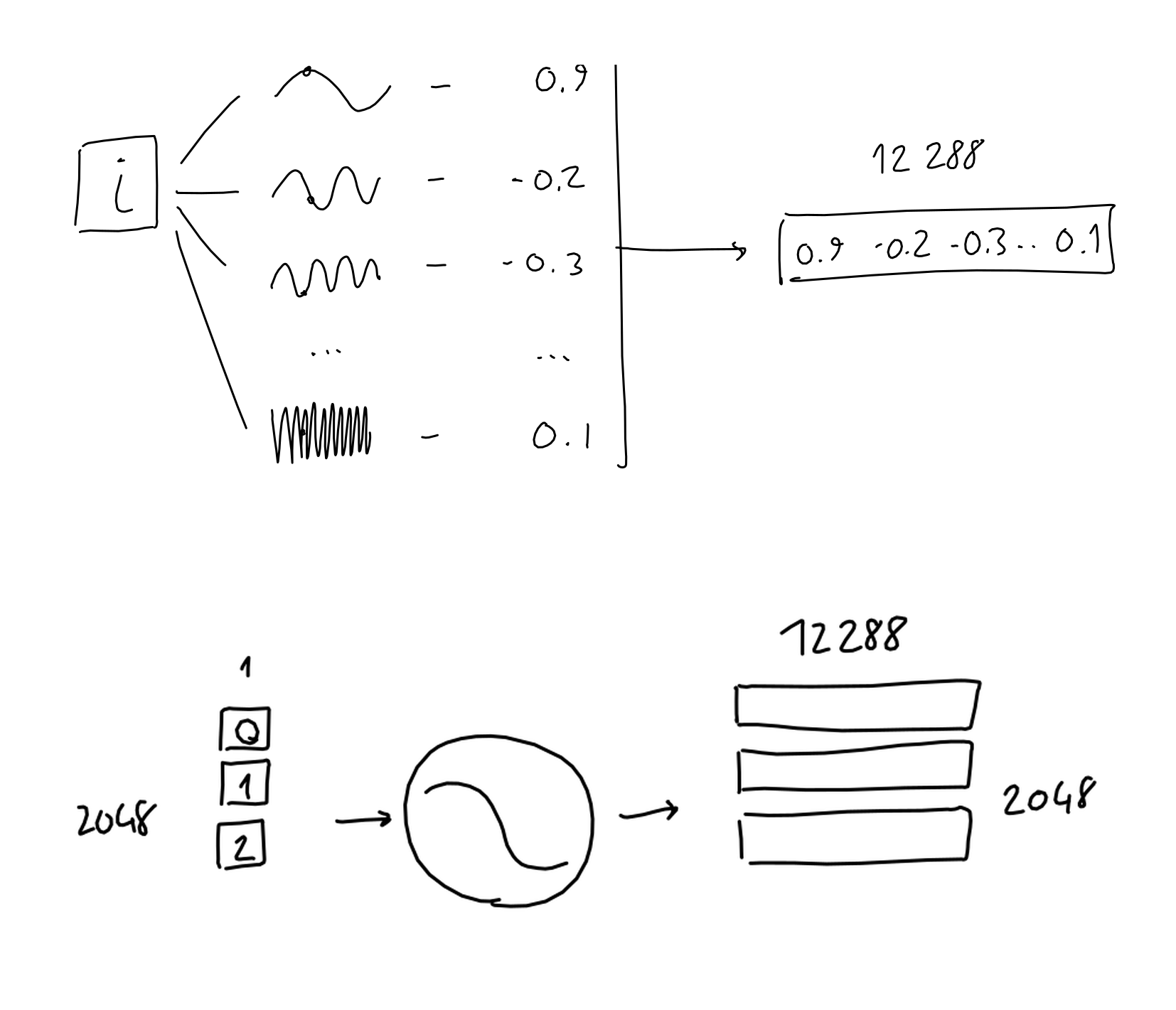
◆位置の符号化
シーケンス内のトークンの位置を変換するため、トークンを0番目から2047番目までで順番付けし、周波数の異なる正弦関数に渡します。2048種類のトークン位置を1万2288種類の正弦関数に渡すことで、2048行×1万2288列の行列が生成されます。
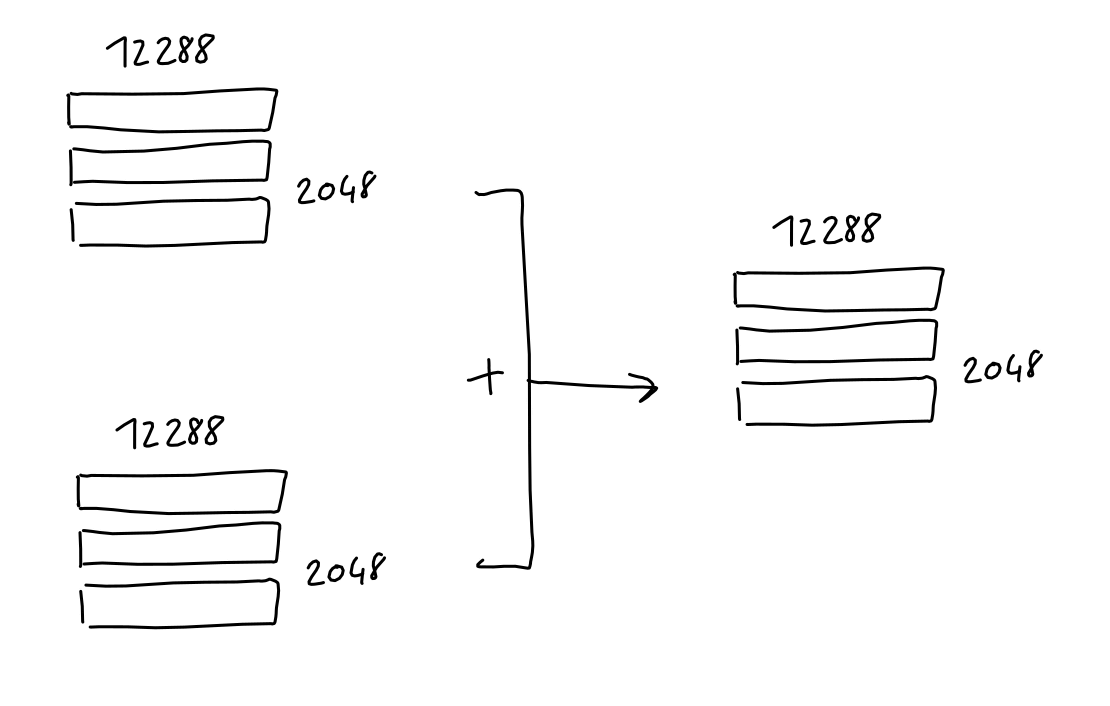
位置変換後の行列はトークンの埋め込み行列に加算が可能され、2048行×1万2288列の符号化済み行列が生成されます。
◆アテンション
アテンションとは「入力データのどの部分に注意を向けるのか」ということで、深層学習において非常に重要な機構となります。
例えば、3つのトークンを符号化した3行×512列の行列があり、AIモデルが3つの線形射影を学習していたとします。3つの符号化行列からこの3つの線形射影によって、3種類の3行×64列の行列が生成されます。
このうち2つの行列はクエリ(Q)とキー(K)と呼ばれます。このQとKの転置行列(KT)を掛け合わせて生成される3行×3列の行列(Q・KT)は、各トークンの他のトークンに対する重要度を示します。
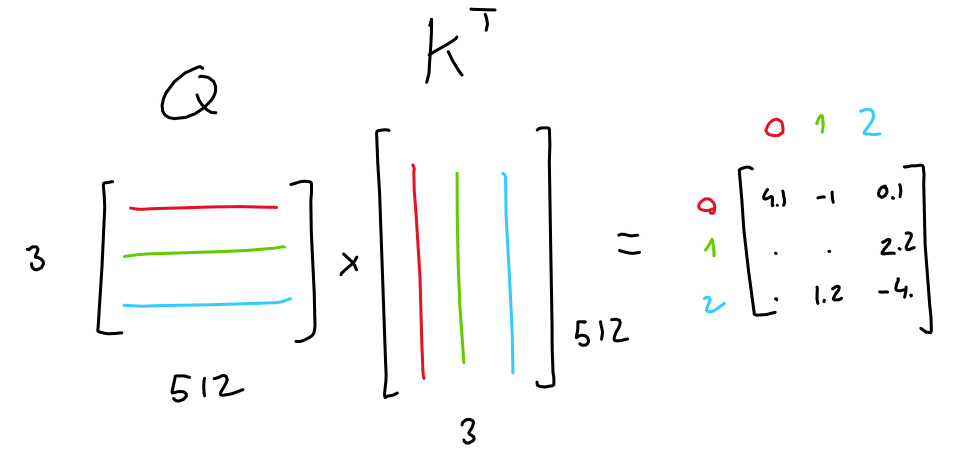
そして、3つ目の3列×512行の行列であるバリュー(V)をQ・KTに乗算することで、それぞれのトークンの重要度によって重み付けされた3行×512列の行列が生成されます。
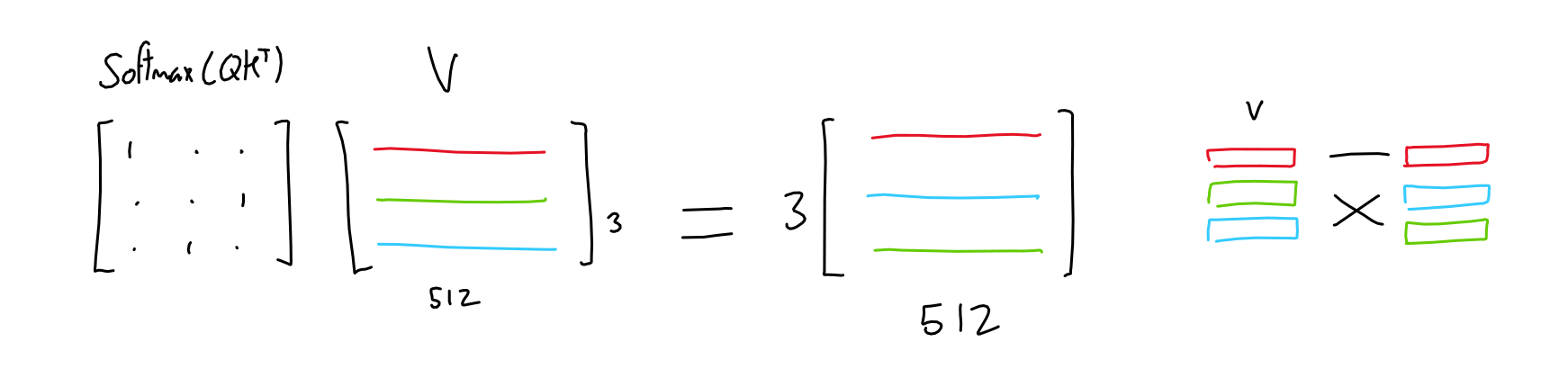
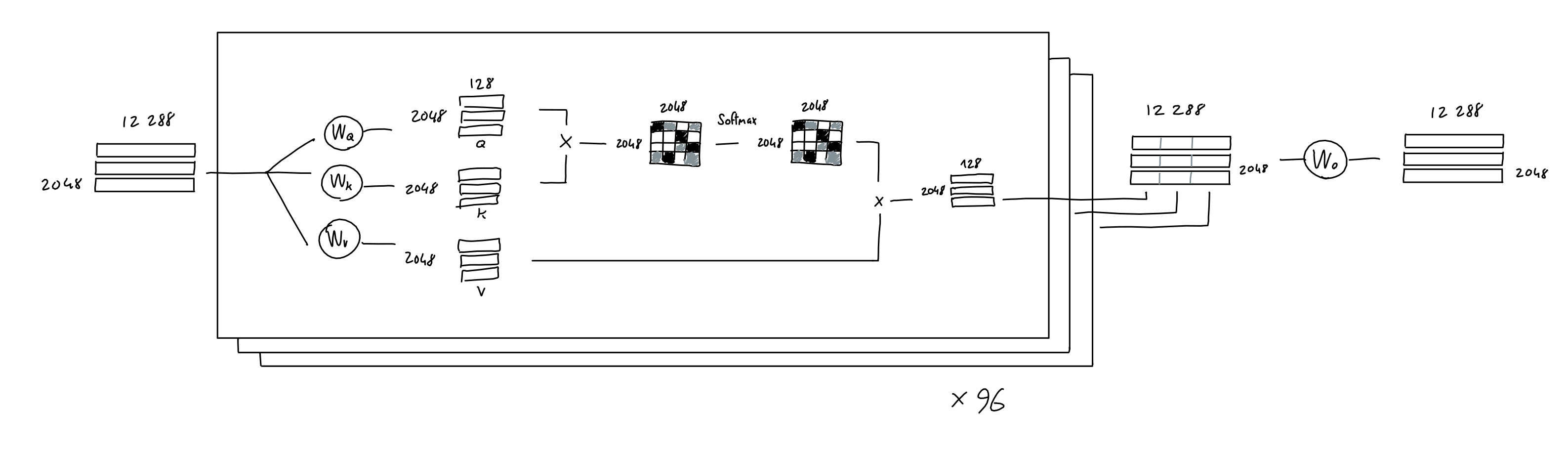
GPTモデルは「マルチヘッドアテンション」と呼ばれる仕組みを採用しています。具体的には、「2048行×12288列の符号化済み行列から、3種類の線形射影によって2048行×128列のQ・K・Vが生成され、(Q・KT)・V=2048行×128列の行列を生成する」というプロセスを96回繰り返し、連結することで2048行×1万2288列の行列を生成します。この行列をさらに線形射影して、新たに2048行×1万2288列のアテンション済み行列を生成します。
◆フィードフォワード
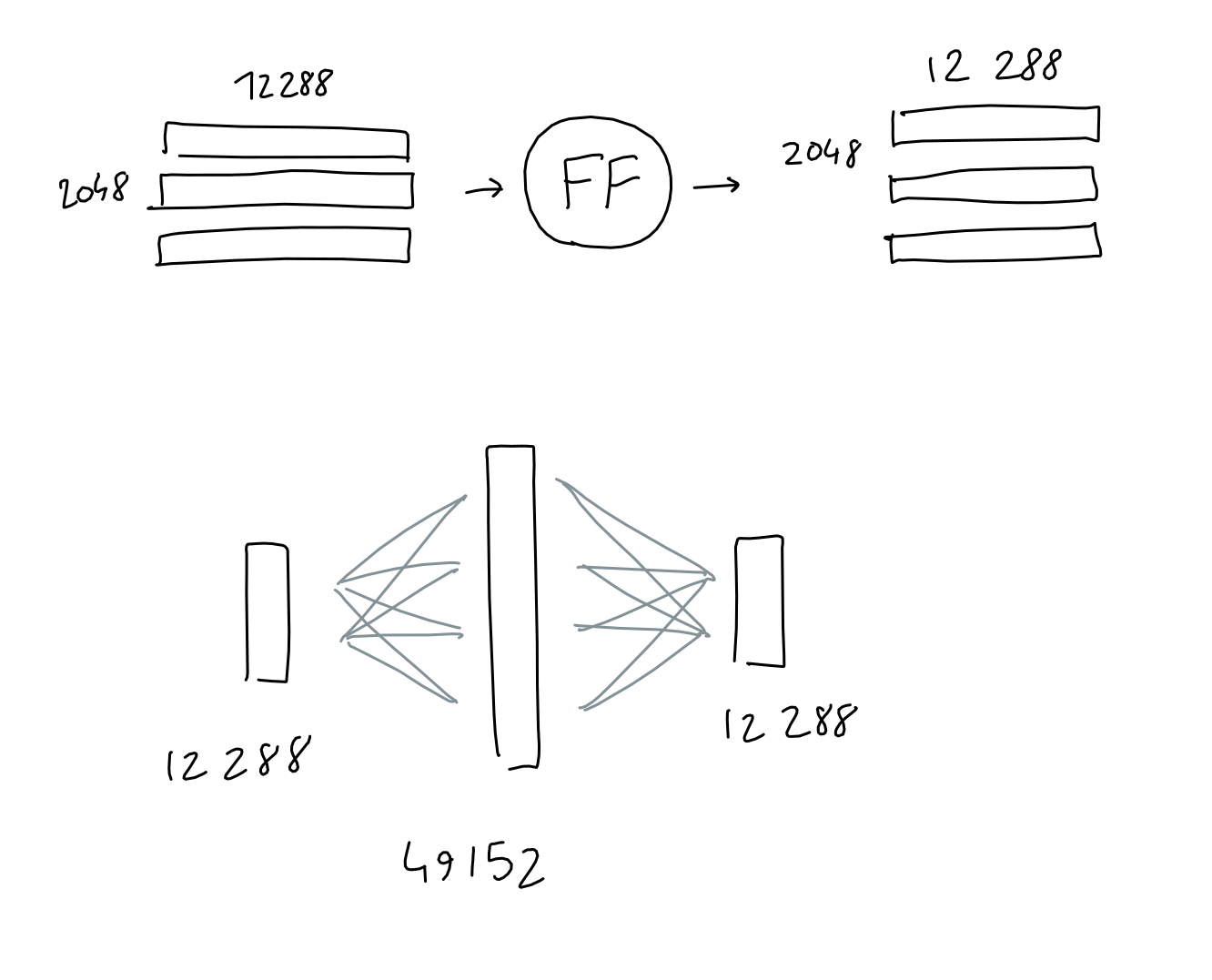
フィートフォワードは1つの中間層を持つ多層パーセプトロンで、入力に学習した重み(中間層)を掛け合わせてバイアスを加え、もう一度同じことをして結果が得るというものです。
GPT-3の場合は4×1万2288=4万9152のサイズをもつ中間層をもっていますが、2048行×1万2288列の行列を入力して出力されるのは同じ2048行×1万2248列です。
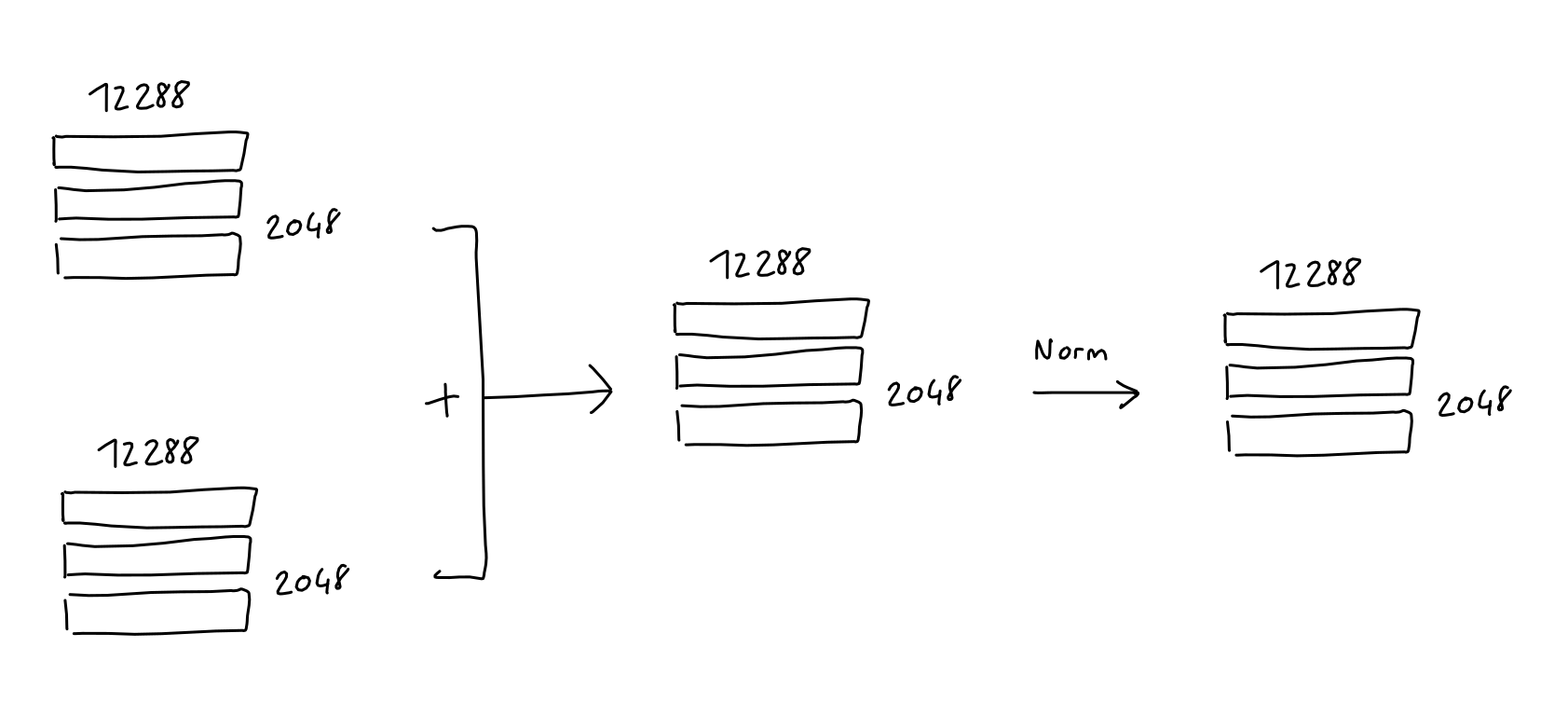
マルチヘッドアテンションとフィードフォワードが終わった後でそれぞれ、各ブロックの入力をその出力に加算し、結果を正則化します。つまり、アテンションの後に正則化し、その後にフィートフォワードを行って再度正則化するという流れになります。
◆復号化
アテンションとフィードフォワードを通過して正則化された2048行×1万2288列の行列には、2048個の出力位置ごとに、どの単語が現れるべきかという情報が、12288個のベクトルとして含まれているはず。ここで、「埋め込み」で行った処理の逆を行い、2048行×5万257列の行列に変換します。
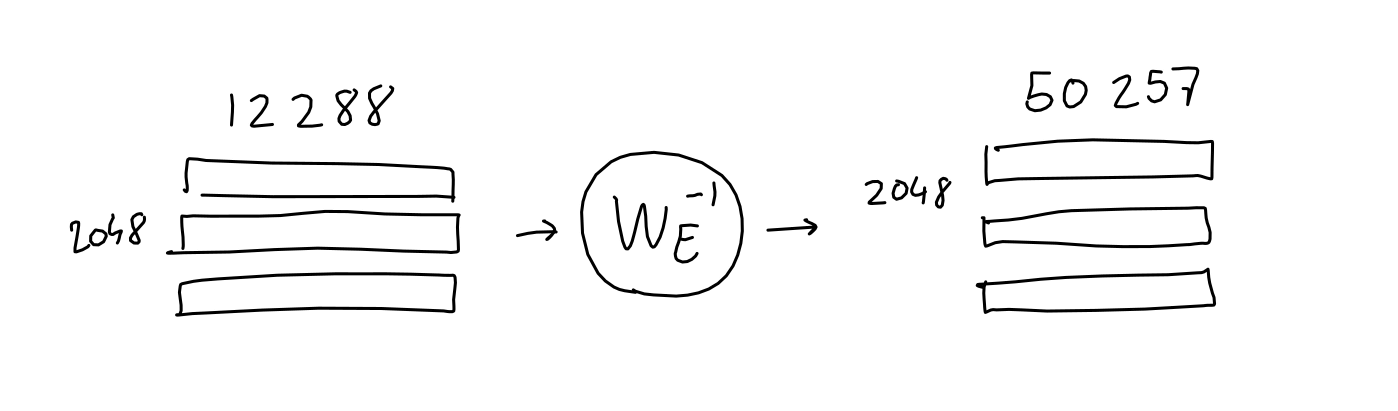
この方法では、最初の入力シーケンス由来の行列のように0と1のみで構成された行列を得ることはできませんが、ソフトマックスによって確率分布に変換することができます。さらに、GPTの論文ではパラメーター「top-k」に言及されています。このtop-kは出力に含まれる可能性のある単語の量を、予測される単語のうち最も可能性の高いk個に限定するというものです。例えばk=1の場合、常に最も可能性の高い言語を選択します。
以上のように、GPTは複雑な数学的行程を経ることで、言語を処理することが可能になっています。なお、デュガス氏がGPTの処理行程をまとめた図は以下から見ることができます。

この記事のタイトルとURLをコピーする

