



















画像生成AI「Stable Diffusion」では、文章(プロンプト)を入力することで自由に画像を生成できます。しかし、自分好みの画像を生成するにはプロンプトにこだわる必要があり、慣れるまでは「好みの画像をサクッと生成」とはいきません。「Tagger for Automatic1111’s Web UI」を使えば参考画像の要素を読み取ってDanbooruのタグを導き出し、「参考画像に似た画像」を生成可能なプロンプトを一発で作成できるとのことなので、実際に使ってみました。
GitHub – toriato/stable-diffusion-webui-wd14-tagger: Tagger for Automatic1111’s Web UI
https://github.com/toriato/stable-diffusion-webui-wd14-tagger
Tagger for Automatic1111’s Web UIは、Stable Diffusionを簡単に扱えるUI「Stable Diffusion web UI(AUTOMATIC1111版)」向けの拡張機能として提供されています。Stable Diffusion web UI(AUTOMATIC1111版)のインストール手順は、以下の記事で詳しく確認できます。

Stable Diffusion web UI(AUTOMATIC1111版)をインストールしたら、起動して画面上部の「Extensions」をクリックしてから「Install from URL」を選択。続いて入力欄に「https://github.com/toriato/stable-diffusion-webui-wd14-tagger」と入力してから「Install」をクリックします。

インストールが完了したら「Installed」をクリックして「Apply and restart UI」をクリック。

その後、Stable Diffusion web UI(AUTOMATIC1111版)を再起動すればTagger for Automatic1111’s Web UI本体のインストールは完了です。

本体のインストールが完了したら、必要なモデルデータをダウンロードします。まず、DeepDanbooruモデルの配布ページにアクセスして、「deepdanbooru-v3-20211112-sgd-e28.zip」(571MB)と「deepdanbooru-v4-20200814-sgd-e30.zip」(258MB)をダウンロード。
モデルデータはZIP形式で配布されているので、ダウンロード後に解凍します。
解凍して現れたフォルダを、Stable Diffusion web UI(AUTOMATIC1111版)のインストールフォルダ内にある「models」フォルダの中に移動させます。
こんな感じに、「models」フォルダ内に2つのフォルダが表示されたらOK。
次に、Discord上で配布されている「MrSmilingWolf’s氏が作成したモデル」をダウンロードするべく、招待リンクからDiscordサーバーに参加します。今回は既にDiscordアカウントを持っているので「既にアカウントをお持ちですか?」をクリックしました。

続いて、メールアドレスとパスワードを入力してから「ログイン」をクリック。
以下のように「SD Training Labs」サーバーに参加できたらOK。
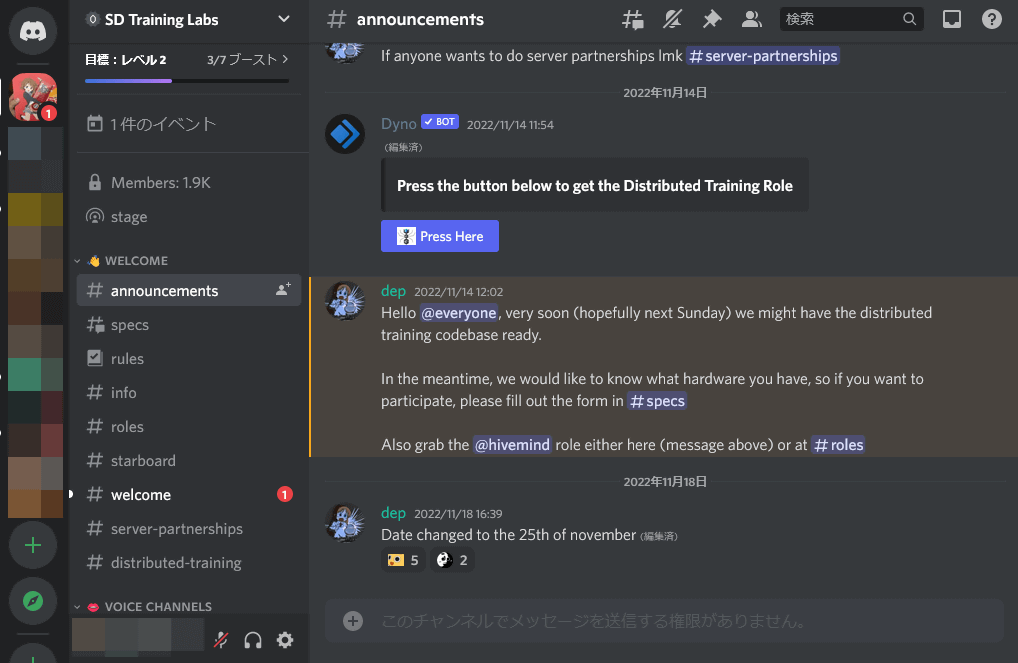
続いて配布リンクが含まれるメッセージに移動し、赤枠で囲まれたURLをクリックします。
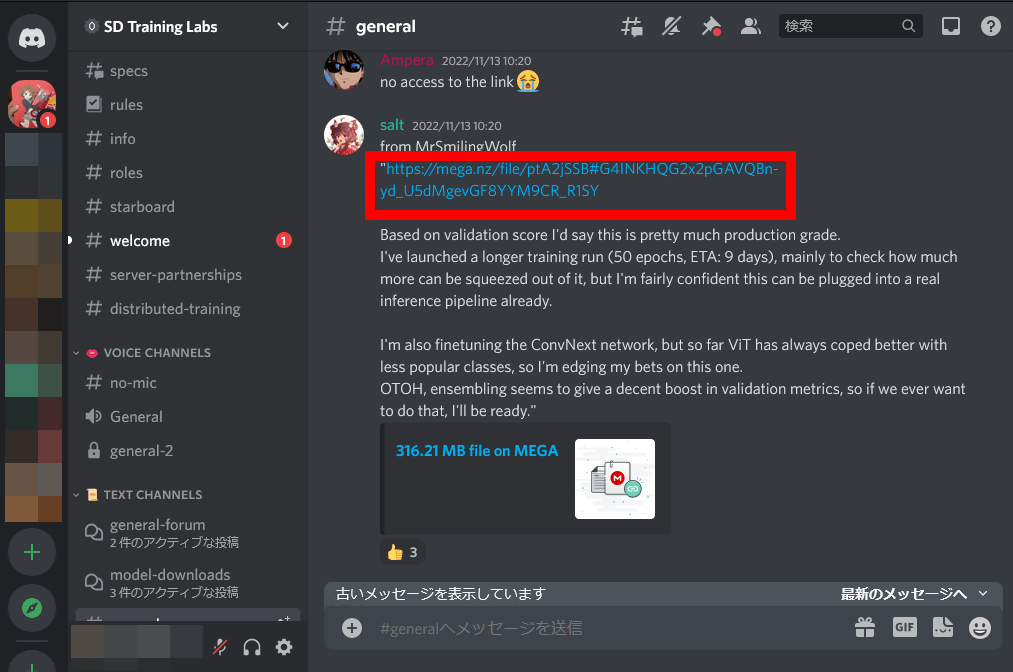
すると、目的のモデル(316.2MB)の配布ページにアクセスできるので「ダウンロード」をクリックします。
モデルは7z形式で圧縮されているので「Explzh」などの対応ソフトで解凍します。

解凍したフォルダの中身を、Stable Diffusion web UI(AUTOMATIC1111版)のインストールフォルダ内の「extensions」の中の「stable-diffusion-webui-wd14-tagger」フォルダの中に移動させます。
「stable-diffusion-webui-wd14-tagger」内に以下のようなファイルが存在するようになればOK。これでTagger for Automatic1111’s Web UIを使う準備は完了です。
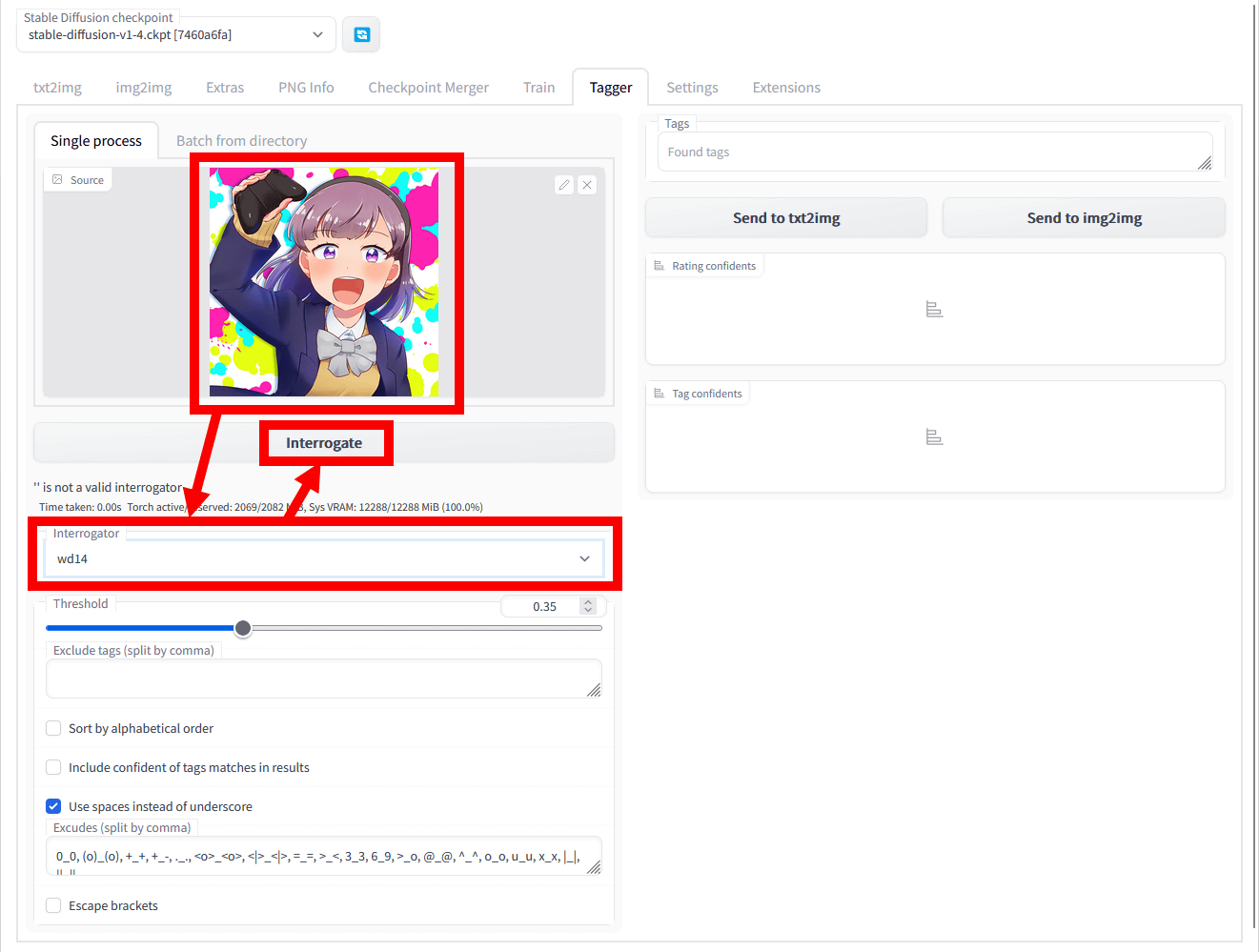
Tagger for Automatic1111’s Web UIの使い方は簡単。まず、左上の画像入力欄に参考画像を入力し、下部の「Interrogator」で「wd14」を選択した後、「Interrogate」をクリックするだけです。今回は、フルカラー漫画「姫とゲーマー」の画像を参考画像に指定しました。
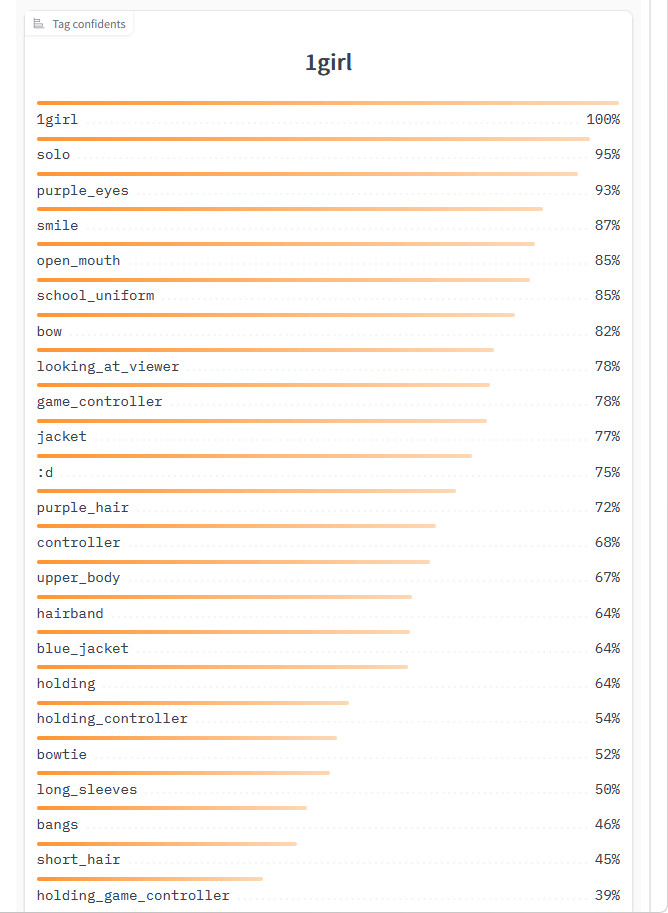
数秒待つと、画面右側に生成されたプロンプトが表示されます。今回は「1girl, solo, smile, bow, jacket, :d, controller, hairband, holding, bowtie, bangs, blazer, shirt, purple eyes, open mouth, school uniform, looking at viewer, game controller, purple hair, upper body, blue jacket, holding controller, long sleeves, short hair, holding game controller」というプロンプトが生成されました。
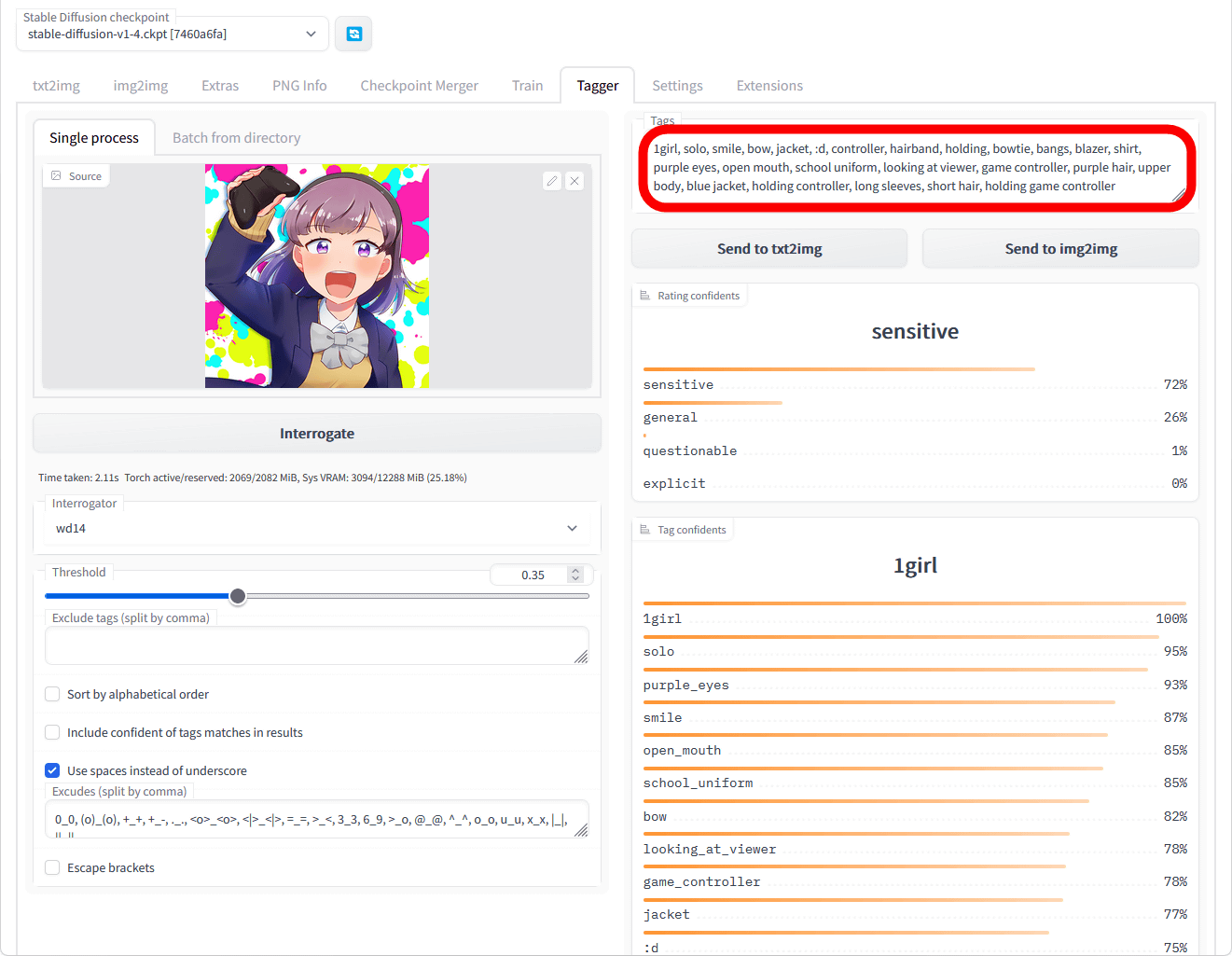
画面を下部にスクロールすると、画像とDanbooruタグの関連率が表示されます。
生成したプロンプトを用いて画像を生成するには、「send to txt2img」をクリックします。
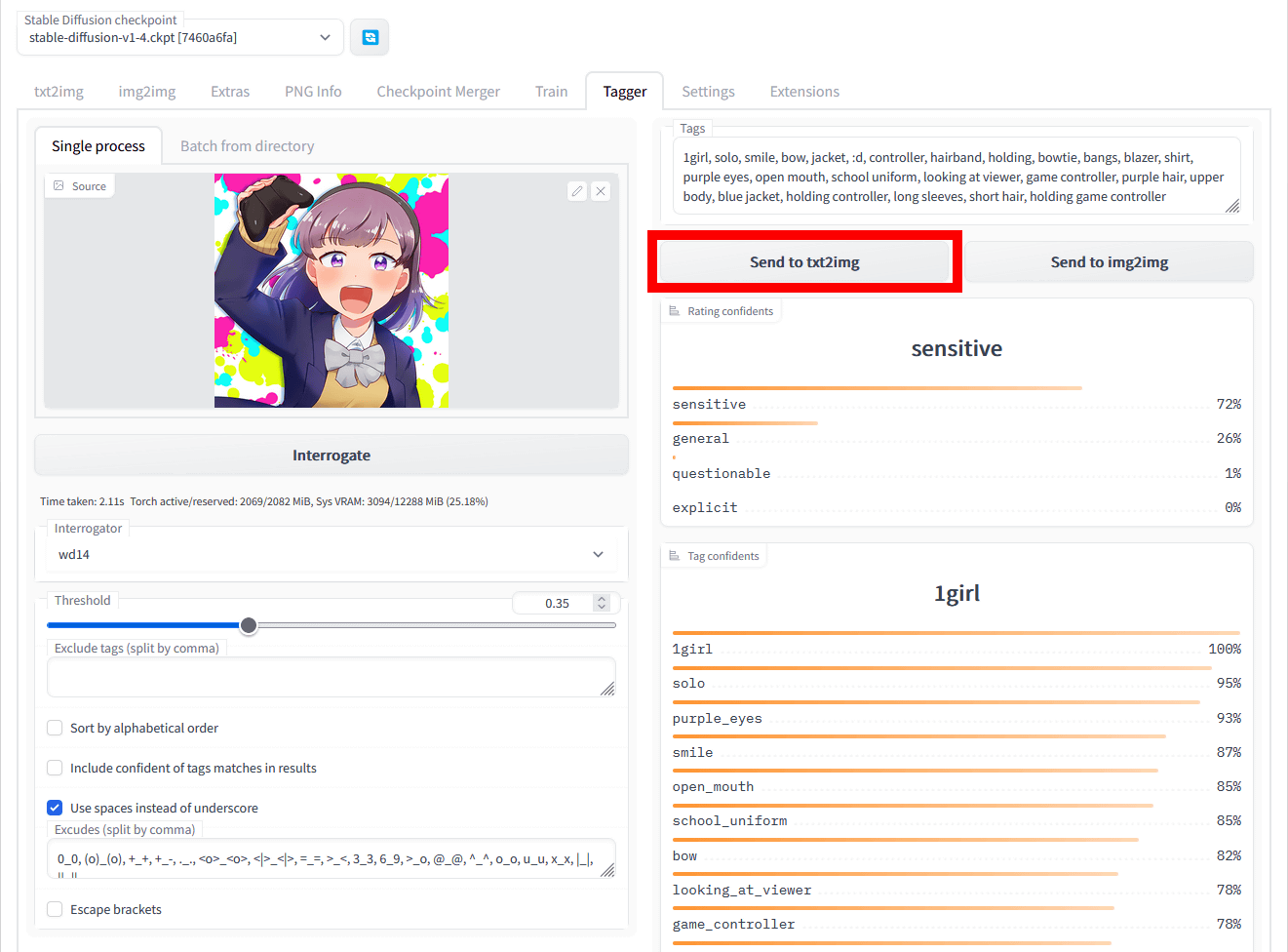
すると、画像生成画面が開くので「Generate」をクリックすれば画像が生成されます。今回はDanbooru上の画像を学習して作られたモデル「Waifu-Diffusion」を用いて画像を生成してみました。

生成結果はこんな感じ。参考画像に含まれる「ブレザー着用」「口を開ける」「紫の瞳」「ゲームのコントローラーを持っている」といった要素が見事に再現されています。

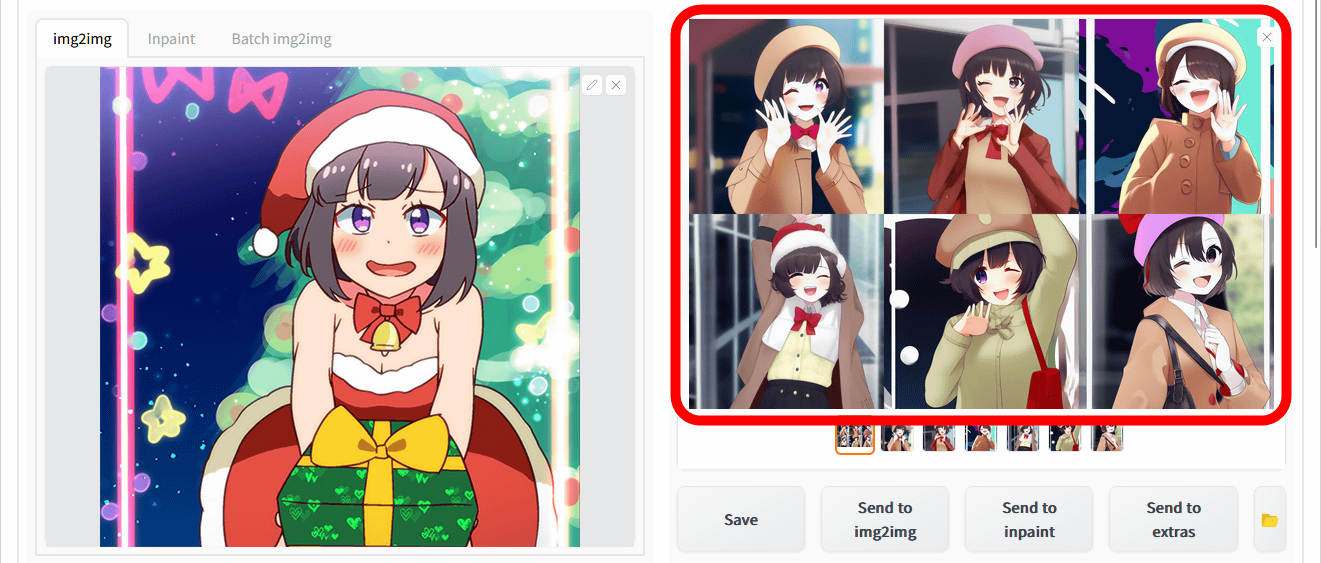
次に、「Send to img2img」をクリックして、img2imgでの画像生成を試してみます。
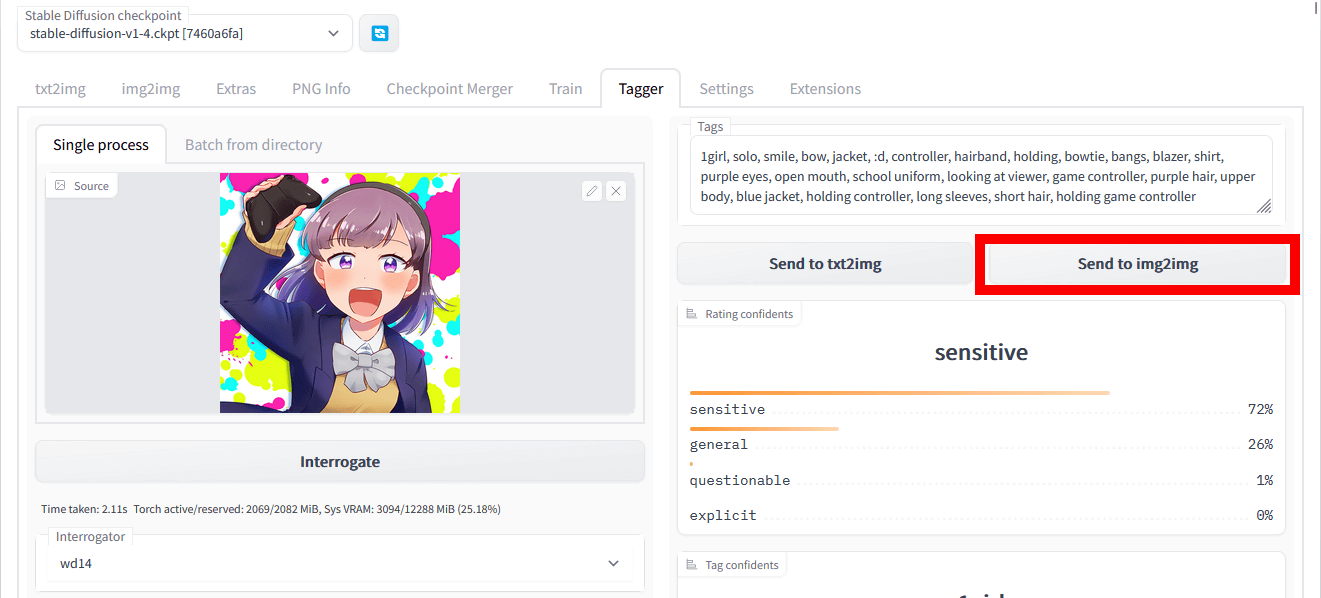
元画像と違う画像を、Tagger for Automatic1111’s Web UIで生成したタグと一緒に入力して生成した結果がこんな感じ。指定した画像の構図や背景の雰囲気は維持しつつ「ブレザー着用」「口を開ける」「紫の瞳」「ゲームのコントローラーを持っている」といった特徴をもった画像を生成できました。

今度は、同じキャラクターを描いた別シーンの画像を参考画像に指定してみます。生成されたプロンプトは「1girl, solo, bow, bag, smile, ;d, hat, handbag, blush, coat, beret, bangs, waving, one eye closed, open mouth, purple eyes, red headwear, red bow, arm up, hair bow, black hair, long sleeves, short hair, shoulder bag, looking at viewer, upper body, brown coat, hat bow」です。
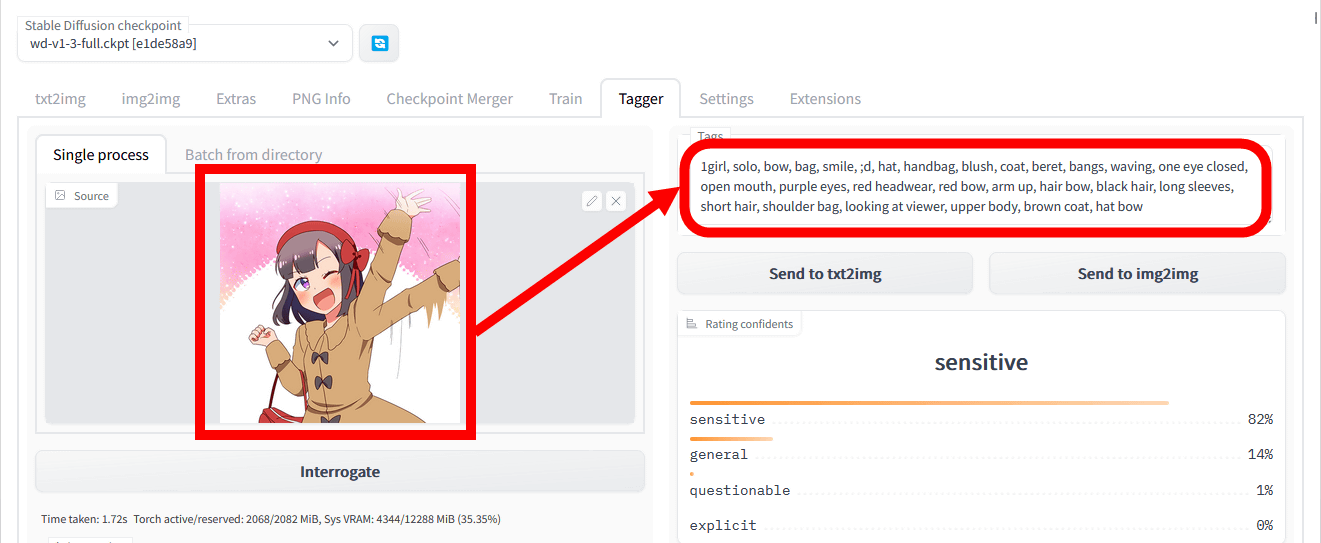
上記のプロンプトを用いてtxt2imgで画像を生成した結果、以下のような画像が出力されました。

1枚目の画像と同様にimg2imgでの画像生成も試してみました。参考画像に含まれる「茶色いコート着用」「片目を閉じる」といった特徴が維持されつつ、体の向きや小物の一部が入力画像に近くなっています。
この記事のタイトルとURLをコピーする

